Explorando o DeepFakes

Em dezembro de 2017, um usuário chamado “DeepFakes” postou vídeos explícitos com aparência realista de celebridades famosas no Reddit. Ele gerou esses vídeos falsos usando aprendizado profundo, o mais recente em IA, para inserir rostos de celebridades em filmes adultos.
Nas semanas seguintes, a internet explodiu com artigos sobre os perigos da tecnologia de troca de rostos: assediar inocentes, divulgar notícias falsas e prejudicar a credibilidade das evidências em vídeo para sempre.
É verdade que maus atores usarão essa tecnologia para causar danos; mas, como o gênio está fora da garrafa, não devemos parar para pensar no que mais o DeepFakes poderia ser usado?
Nesta postagem, exploro os recursos dessa tecnologia, descrevo como ela funciona e discuto os aplicativos em potencial.
Mas primeiro: o que é o DeepFakes e por que isso importa?
O DeepFakes oferece a capacidade de trocar uma face por outra em uma imagem ou vídeo. A troca de rosto é realizada em filmes há anos, mas exigia que editores de vídeo e especialistas em CGI passassem muitas horas para obter resultados decentes.
A nova inovação é que, usando técnicas de aprendizado profundo, qualquer pessoa com uma GPU poderosa e dados de treinamento, pode criar vídeos falsos críveis.
Isso é tão notável que vou repetir: qualquer pessoa com centenas de imagens de amostra, da pessoa A e da pessoa B, pode alimentá-las em um algoritmo e produzir trocas de rosto de alta qualidade - não são necessárias habilidades de edição de vídeo.
Isso também significa que isso pode ser feito em escala e, como muitos de nós temos nossos rostos on-line, é fácil inserir quase qualquer pessoa em vídeos falsos. Assustador, mas espero que não seja só tristeza, afinal de contas, nós, como sociedade, passamos a aceitar que as fotos podem ser falsificadas facilmente.

Gerar rostos não é novidade: em Star Wars Rogue One, uma atriz, juntamente com um pouco de magia CGI, foi usada para recriar uma jovem Carrie Fisher. Os pontos ajudaram a mapear seu rosto com precisão ( saiba mais aqui ). Isso não é o DeepFakes, mas esse é o tipo de coisa que o DeepFakes permite que você faça sem nenhuma habilidade.
Explorando o que o DeepFakes é capaz
Antes de pensar em como usar essa tecnologia, eu queria saber como ela funciona e como ela é executada.
Escolhi dois apresentadores de TV populares à noite, Jimmy Fallon e John Oliver, porque posso encontrar muitos vídeos deles com poses e iluminação semelhantes - e também variação suficiente (como batalhas de sincronização labial ) para mantê-lo interessante.

Felizmente para mim, há um repositório ativo do GitHub que contém o código original do DeepFakes e muitas outras melhorias. É bastante simples de usar, mas o ônus ainda é de o usuário coletar e preparar dados de treinamento.
Para facilitar a experimentação, escrevi um script para trabalhar diretamente com os vídeos do YouTube. Isso torna a coleta e o pré-processamento de dados de treinamento simples e a conversão de vídeos em uma etapa. Clique aqui para ver meu repositório do Github e ver com que facilidade geramos os vídeos abaixo (também compartilho meus pesos de modelo).

Fácil: o meu script faceit.py permite que você especifique uma lista de vídeos do YouTube para cada pessoa. Em seguida, execute comandos para pré-processar (baixar vídeos do YouTube, extrair quadros, encontrar rostos), treinar e converter vídeos com áudio e opções para redimensionar, mostrar lado a lado etc.
Resultados: Jimmy Fallon e John Oliver
Os vídeos a seguir foram gerados treinando um modelo em cerca de 15 mil imagens do rosto de cada pessoa (30 mil imagens no total). Eu tenho rostos para cada celebridade de 6 a 8 vídeos do YouTube, de 3 a 5 minutos cada, com 20 quadros por segundo por vídeo e filtrando os quadros que não têm o rosto presente. Tudo isso foi feito automaticamente - tudo o que fiz foi especificar uma lista de URLs de vídeo do YouTube.
O tempo total de treinamento foi de aproximadamente 72 horas em uma GPU NVIDIA GTX 1080 TI. O treinamento é restrito principalmente pela GPU, mas o download de vídeos e a divisão deles em quadros é vinculado à E / S e pode ser paralelo.
Observe que, embora eu tenha milhares de imagens de cada pessoa, é possível obter trocas de rosto decentes com apenas 300 imagens. Eu segui esse caminho porque extraí imagens de rosto de vídeos e é muito mais fácil escolher um punhado de vídeos como dados de treinamento do que encontrar centenas de imagens.
As imagens abaixo são de baixa resolução para manter pequeno o tamanho do arquivo GIF animado. Há um vídeo do YouTube abaixo com maior resolução e som.

Oliver tocando a música de Iggy Azalea, Fancy. O algoritmo funciona bem, mesmo com o microfone no caminho.

Aqui está Oliver hospedando o show de Fallon. Observe que o rosto fica com óculos, mas o cabelo e o formato do rosto são intocados.

Boa conversa para o treinador das Olimpíadas. O algoritmo aprendeu o suficiente para fazer o “DO IT!” De Oliver parecer real.

Por favor, não assista a isso, a menos que queira ver John Oliver dançando ao som de música.
Embora não sejam perfeitos, os resultados acima são bastante convincentes. A principal coisa a lembrar é: o algoritmo aprendeu como fazer isso vendo muitos exemplos, não modifiquei os vídeos de forma alguma. Mágico? Vamos olhar embaixo das cobertas.
Como funciona?
No centro do código do Deepfakes está um autoencoder , uma rede neural profunda que aprende como obter uma entrada, compactá-la em uma pequena representação ou codificação e depois regenerar a entrada original dessa codificação.
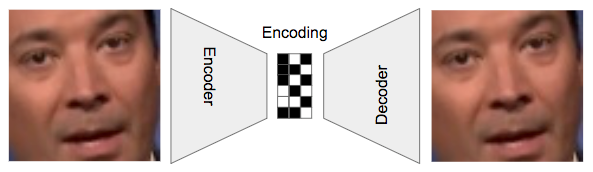
Nesta configuração padrão do autoencoder, a rede está tentando aprender como criar uma codificação (os bits do meio), a partir da qual pode regenerar a imagem original. Com dados suficientes, ele aprenderá como fazer isso.
Colocar um gargalo no meio força a rede a recriar essas imagens em vez de apenas retornar o que vê. As codificações ajudam a capturar padrões mais amplos, hipoteticamente, como e onde desenhar a sobrancelha de Jimmy Fallon.
O Deepfakes vai além ao ter um codificador para comprimir uma face em uma codificação e dois decodificadores, um para transformá-lo novamente na pessoa A (Fallon) e o outro na pessoa B (Oliver). É mais fácil entender com um diagrama:
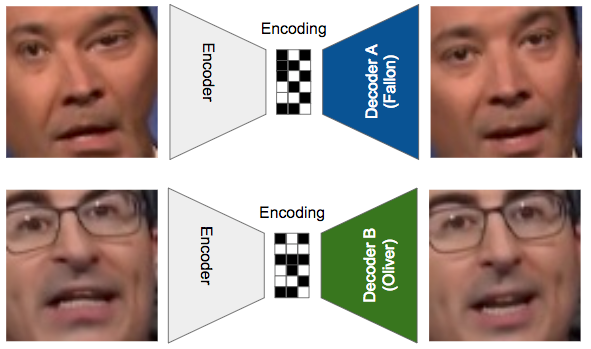
Há apenas um codificador que é compartilhado entre os casos Fallon e Oliver, mas os decodificadores são diferentes. Durante o treinamento, as faces de entrada são distorcidas, para simular a noção de “queremos uma face assim”.
Acima, mostramos como esses três componentes são treinados:
- Passamos uma imagem distorcida de Fallon para o codificador e tentamos reconstruir o rosto de Fallon com o decodificador A. Isso força o decodificador A a aprender como criar o rosto de Fallon a partir de uma entrada barulhenta.
- Em seguida, usando o mesmo codificador, codificamos uma versão distorcida do rosto de Oliver e tentamos reconstruí-lo usando o decodificador B.
- Continuamos repetindo isso até que os dois decodificadores possam criar seus respectivos rostos, e o codificador aprendeu a “capturar a essência de um rosto”, seja Fallon ou Oliver.
Depois que o treinamento estiver concluído, podemos executar um truque inteligente: passar uma imagem de Fallon para o codificador e, em vez de tentar reconstruir Fallon a partir da codificação, passamos agora para o decodificador B para reconstruir Oliver.
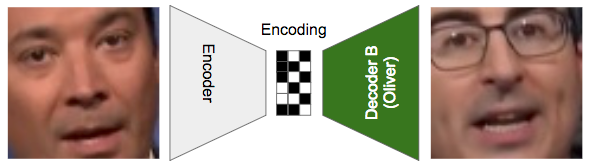
É assim que executamos o modelo para gerar imagens. O codificador captura a essência do rosto de Fallon e o entrega ao decodificador B, que diz “ah, outra entrada barulhenta, mas eu aprendi como transformar isso em Oliver … voila!”
É notável pensar que o algoritmo pode aprender a gerar essas imagens apenas vendo milhares de exemplos, mas foi exatamente o que aconteceu aqui e com resultados razoáveis.
Limitações e aprendizados
Embora os resultados sejam empolgantes, existem claras limitações ao que podemos alcançar com esta tecnologia hoje:
-
Só funciona se houver muitas imagens do alvo : para colocar uma pessoa em um vídeo, são necessárias na ordem de 300 a 2000 imagens de seu rosto para que a rede possa aprender como recriá-lo. O número depende da variação dos rostos e da proximidade com o vídeo original. → Isso funciona bem para celebridades ou qualquer pessoa com muitas fotos online. Mas, claramente, isso não permitirá que você crie um produto que possa trocar a cara de qualquer pessoa.
-
Você também precisa de dados de treinamento representativos do objetivo: o algoritmo não é bom em gerar fotos de perfil de Oliver, simplesmente porque não havia muitos exemplos de Oliver olhando para o lado. Em geral, as imagens de treinamento do seu alvo precisam aproximar a orientação, as expressões faciais e a iluminação nos vídeos nos quais você deseja inseri-los.
→ Portanto, se você estiver criando uma ferramenta de troca de rosto para uma pessoa comum, já que a maioria das fotos será voltada para a frente (por exemplo, selfies no Instagram), limite as trocas de rosto para a maioria dos vídeos voltados para a frente. Se você estiver trabalhando com uma celebridade, é mais fácil obter um conjunto diversificado de imagens. E se seu objetivo estiver ajudando você a criar dados, procure quantidade e variedade para inseri-los em qualquer coisa.

Não havia muitas imagens de Oliver olhando para o lado, então a rede nunca foi capaz de aprender pelo exemplo e gerar poses de perfil.
- Os modelos de construção podem ficar caros : foram necessárias 48 horas para obter bons resultados e 72 para obter os mais justos acima. Por cerca de US $ 0,50 por hora da GPU, custará US $ 36 para construir um modelo apenas para a troca da pessoa A para B e vice-versa, e isso não inclui toda a largura de banda necessária para obter dados de treinamento e CPU e E / S para pré-processá-los. . O maior problema: você precisa de um modelo para cada par de pessoas, para que o trabalho investido em um único modelo não seja dimensionado para diferentes faces. (Nota: usei uma única máquina de GPU; o treinamento pode ser paralelo entre as GPUs.) → Esse alto custo de criação de modelo dificulta a criação de um aplicativo gratuito ou barato, na esperança de que ele se torne viral. Obviamente, não é um problema se os clientes estão dispostos a pagar para gerar modelos.
- A execução de modelos é bastante barata, mas não gratuita: leva de 5 a 20X a duração de um vídeo para criar uma troca ao executar em uma GPU, por exemplo, um vídeo 1080p de 1 minuto leva cerca de 18 minutos para ser gerado. Uma GPU ajuda a acelerar o modelo principal e também o código de detecção de rosto (ou seja, existe um rosto nesse quadro que eu precise trocar?). Eu não tentei a conversão em apenas uma CPU, mas arriscaria que seria muito mais lento. → Existem muitas ineficiências no processo de conversão atual: aguardar E / S ao ler e escrever quadros, sem lotes de quadros enviados para a GPU, sem paralelismo etc. Isso pode ser feito para funcionar muito mais rápido e, possivelmente, com uma troca de tempo e custo que permite que as CPUs fiquem bem na conversão.
- A reutilização de modelos reduz o tempo de treinamento e, portanto, o custo : se você usar o modelo de Fallon para Oliver para converter, digamos, o rosto de Jimmy Kimmel para John Oliver, os resultados serão geralmente muito ruins. No entanto, se você treinar um novo modelo com imagens de Kimmel e Oliver, mas começar com o modelo treinado de Fallon para Oliver, ele poderá aprender como realizar conversões razoáveis em 20 a 50% do tempo (12 a 36 horas em vez de Mais de 72 horas). →Se alguém mantiver modelos estáveis para diferentes formatos de rosto e usá-los como ponto de partida, poderá haver reduções consideráveis em tempo e custo.
Esses são problemas possíveis para ter certeza: ferramentas podem ser construídas para coletar imagens de canais on-line em massa; algoritmos podem ajudar a sinalizar quando há dados de treinamento insuficientes ou incompatíveis; otimizações inteligentes ou reutilização de modelos podem ajudar a reduzir o tempo de treinamento; e um sistema bem projetado pode ser construído para tornar todo o processo automático.
Mas, finalmente, a pergunta é: por quê? Existe um modelo de negócios suficiente para fazer com que tudo isso valha a pena?
Então, quais aplicativos em potencial existem?
Dado o que agora aprendemos sobre o que é possível, vamos falar sobre maneiras pelas quais isso pode ser útil:
Produção de conteúdo de vídeo
Hollywood tinha essa tecnologia na ponta dos dedos, mas não a esse baixo custo. Se eles conseguirem criar ótimos vídeos com essa técnica, isso mudará a demanda de editores qualificados ao longo do tempo.
Mas também poderia abrir novas oportunidades: por exemplo, fazer filmes com atores desconhecidos e, em seguida, sobrepor celebridades famosas a eles. Isso pode funcionar para vídeos do YouTube ou mesmo canais de notícias filmados por pessoas comuns.
Em cenários mais distantes, os estúdios podem mudar de ator com base em seu mercado-alvo (mais Schwarzenager para os austríacos) ou a Netflix pode permitir que os espectadores escolham atores antes de começarem a jogar. O mais provável é que essa tecnologia possa gerar receita para as propriedades de atores mortos há muito tempo, trazendo-os de volta à vida.

O Deepfakes é a ponta do iceberg no que diz respeito aos métodos de geração de vídeo. O vídeo acima demonstra uma abordagem para construir um modelo 3D controlável de uma pessoa a partir de uma coleção de fotos ( artigo 2015). O principal autor desse artigo tem outro trabalho interessante que vale a pena examinar ; atualmente ele está no Google Brain.
Aplicativos sociais
Alguns dos tópicos de comentários dos vídeos do DeepFakes no YouTube falam sobre o grande gerador de memes que essa tecnologia poderia criar. Jib Jab é uma empresa que vende cartões de vídeo com trocas simples de rosto há anos (eles são hilários). Mas a grande oportunidade é criar o próximo grande sucesso viral; afinal de contas, os filtros de fotos atraíram muitas pessoas ao Instagram e ao SnapChat, e os aplicativos de troca de rosto já foram bem antes.
Dado o quão divertidos os resultados podem ser, provavelmente há espaço para um aplicativo viral de sucesso se você puder obter os custos baixos o suficiente para gerar esses modelos.

StarGAN é um trabalho de pesquisa que demonstra a geração de diferentes cores de cabelo, sexo, idade e até expressão emocional usando apenas um algoritmo. Aposto que um aplicativo que permite gerar rostos carnudos pode se tornar viral.
Licenciamento de rostos de celebridades
Imagine se a Target pudesse ter uma celebridade exibindo suas roupas por um mês, pagando uma taxa à agente dela, pegando alguns tiros na cabeça existentes e clicando em um botão. Isso criaria um novo fluxo de receita para celebridades, influenciadores de mídia social ou qualquer pessoa que esteja no centro das atenções no momento. E daria às empresas outra ferramenta para promover marcas e impulsionar a conversão. Também levanta questões legais interessantes sobre a propriedade da semelhança e questões de modelo de negócios sobre como particionar e precificar direitos de uso.

As faces de licenciamento já estão acontecendo. A Looklet é uma empresa que permite às empresas de vestuário: (1) fotografar suas roupas em um manequim, (2) escolher as roupas que acompanham, (3) escolher o rosto e a pose de uma modelo, e pronto, ter uma imagem brilhante pronta para o marketing. Além do mais: eles podem reestilizar à vontade, sem modelos ou fotógrafos.
Publicidade personalizada
Imagine um mundo em que os anúncios que você vê enquanto navega na Web incluem você, seus amigos e sua família. Embora isso possa parecer assustador hoje, parece tão distante pensar que essa não será a norma daqui a alguns anos?
Afinal, somos criaturas visuais e os anunciantes tentam obter respostas emocionais de nós há anos, por exemplo, a Coca-Cola pode querer transmitir alegria colocando seus amigos em um videoclipe, ou Allstate pode provocar seus medos mostrando sua família em um anúncio de seguro. Ou a abordagem pode ser mais direta: o Banana Republic pode sobrepor seu rosto a um tipo de corpo que combine com o seu e convencê-lo de que vale a pena experimentar as novas jaquetas de couro.
Conclusão
Quem quer que seja o usuário original do Deepfakes, eles abriram uma caixa de perguntas difíceis de Pandora sobre como a geração de vídeos falsos afetará a sociedade. Espero que da mesma maneira que aceitamos que as imagens possam ser falsificadas facilmente, também nos adaptaremos à incerteza do vídeo, embora nem todos compartilhem essa esperança .
O que a Deepfakes também fez foi mostrar como essa tecnologia é interessante. Modelos geradores profundos, como o auto-codificador usado pelo Deepfakes, permitem criar dados de aparência sintética, mas realistas (incluindo imagens ou vídeos), apenas mostrando um algoritmo com muitos exemplos. Isso significa que, quando esses algoritmos forem transformados em produtos, as pessoas comuns terão acesso a ferramentas poderosas que os tornarão mais criativos, esperançosamente para fins positivos.
Já houve algumas aplicações interessantes dessa técnica, como aplicativos de transferência de estilo que fazem suas fotos parecerem pinturas famosas, mas, dado o alto volume e a natureza empolgante da pesquisa que está sendo publicada neste espaço, há claramente muito mais por vir .
Estou interessado em explorar como gerar valor a partir das últimas pesquisas em IA; se você tiver interesse em levar essa tecnologia ao mercado para resolver um problema real, envie- me uma observação.

Exemplos de resultados de um famoso artigo CycleGAN (ICCV 2017), que mostra um algoritmo aprendendo a transformar zebras em cavalos, inverno a verão, e fotos regulares em pinturas impressionistas famosas.
Apêndice
Alguns petiscos divertidos para os curiosos:
- O FakeApp é um aplicativo de desktop gratuito que permite usar a tecnologia Deepfakes, desde que você tenha uma GPU e esteja executando o Windows. Mas esteja avisado, o download e a execução de qualquer coisa potencialmente obscura no seu computador é perigoso, e já houve muita angústia sobre o FakeApp, incluindo um recurso de minerador de criptografia no aplicativo ( mais aqui ).
- Derp Fakes é um canal do YouTube com muitos vídeos engraçados sobre SFW. Eu gosto especialmente deste ; é estrelado por Nicholas Cage como todo mundo em uma cena de O Senhor dos Anéis, e é tecnicamente interessante e hilário.
- O autor original do Deepfakes é desconhecido (e se for Satoshi ? … apenas brincando). Também se acredita que ele / ela não é a pessoa por trás do FakeApp. Enquanto o autor forneceu o código original, eles deixaram várias coisas incertas, como: sob qual licença o código é compartilhado e em que artigo acadêmico, se houver, inspirou sua arquitetura de rede neural?
- O desenvolvimento e a pesquisa do Deepfakes continuam por meio de uma comunidade de colaboradores. Visite o repositório do Github deepfakes/faceswap para encontrar o código mais recente. Verifique também shaoanlu / faceswap-GAN para ver um usuário pesquisar outros modelos (como um GAN), técnicas de mascaramento (como a face gerada é inserida em uma imagem) e até mesmo uma abordagem de um modelo para trocar todos eles (para que você não precise criar modelos para cada par de pessoas).
- Se você quiser ler mais sobre esse fenômeno, confira o artigo original da Motherboard que trouxe isso aos olhos do público; este post em que um usuário do FakeApp troca seu cônjuge em vídeos (SFW) e essa linha do tempo com uma compilação de outras boas leituras. Além disso, poucas horas antes de publicar este post, o NYTimes divulgou minha história! Leia aqui .
- Se você quiser ver outras pesquisas relacionadas , confira este vídeo em que um usuário controla o rosto de outra pessoa em tempo real ; este onde eles geram um vídeo realista de Obama ; e também veja o Lyrebird, um produto que permite gerar áudio realista de outra pessoa , com amostras suficientes de voz para treinar.
Autor: Gaurav Oberoi