Programação Defensiva - Amigo ou Inimigo?
Uma das piores coisas sobre o desenvolvimento incorporado (especialmente em C) é recebendo um valor de retorno de uma função, sem outras informações sobre por que a falha ocorreu. Ele não fornece nenhuma informação sobre de onde o erro surgiu!-1unknown_error
Todos nós estivemos aqui como desenvolvedores incorporados, trazendo novas placas, motoristas, módulos, e aplicações, perguntando por que e como entramos nessa confusão. Raiz causando esses problemas é como descascar uma cebola: cada camada que cavar enquanto depuração, sorrimos um pouco menos e mais algumas lágrimas são derramadas. Esse tipo de problemas são muitas vezes um resultado de erro do desenvolvedor, quer as funções de chamada fora de ordem, na hora errada, ou com argumentos incorretos. Eles também poderiam ser porque o sistema estava em um estado ruim, como fora de memória ou impasse.
O firmware_sabe_que há um problema, e provavelmente sabe_qual é o problema_, mas ainda assim não ajuda a resolver o problema. O software foi construído com “Defensivo Programação” práticas em mente, o que permite que o firmware continue funcionando mesmo quando ocorre um comportamento incorreto.
Normalmente, eu preferiria que o firmware falhasse, imprimisse um erro útil e guiasse me exatamente para onde o assunto está. Este é o princípio norteador de “Ofensivo Programação”, que vai um passo além de “Programação Defensiva”.
Neste artigo, vamos mergulhar no que a programação defensiva e ofensiva são, onde a programação defensiva fica aquém, como os desenvolvedores devem pensar em usar los dentro de sistemas embarcados, e como as técnicas de programação ofensiva podem surgir bugs e ajudar os desenvolvedores a causar-los imediatamente no tempo de execução.
Levando a programação defensiva e ofensiva ao extremo, você será capaz de rastrear esses bugs de 1 em 1.000 horas, eficientemente raiz causa-los, e manter seus usuários finais felizes. E, como bônus, mantenha sua sanidade.
Para saber mais sobre as melhores práticas de programação ofensiva e defensiva e perguntar me perguntas ao vivo, inscreva-se para o nossowebinar na Febraury 24, 2022.
Como interromper? Inscreva-separa obter nossas últimas postagens diretamente em sua caixa de correio.
Tabela de Conteúdos
- Programação Defensiva
- Programação Ofensiva
- Programação Ofensiva na Prática
- Manipulação do Código Externo & De Aplicativos
- Melhores Práticas
- Conclusão
Programação Defensiva
Programação defensiva é a prática de escrever software para permitir a continuidade operação depois e enquanto experimenta problemas não planejados. Um exemplo simples é verificando depois de chamar, e garantir que o programa graciosamente lida com o caso.NULLmalloc()
void do_something(void) {
uint8_t *buf = malloc(128);
if (buf == NULL) {
// handle this gracefully!
}
}
Programação defensiva soa bem, e é bom! O firmware que escrevemos nunca deve catastroficamente falhar devido a circunstâncias imprevistas, se não quero.
A programação defensiva realmente brilha ao interagir diretamente com o hardware, bibliotecas proprietárias, e entradas externas que não temos controle direto sobre. O hardware pode ter falhas ou se comportar de forma diferente em vários ambientes, bibliotecas pesados muitas vezes são cheios de insetos, eo mundo exterior vai enviar o que quiser sobre protocolos de comunicação.
Como na maioria das coisas, a programação defensiva pode ser abusada e os benefícios se tornam superado pelos negativos. Se muitos módulos estiverem em camadas em cima um do outro, cada um usando técnicas de programação defensiva, bugs podem e serão criados, perdidos, e/ou obscurecido.
Problemas com programação defensiva
A chave para a programação defensiva é usá-lo nas interfaces exteriores do seu firmware. Deve haver uma parede fina, mas robusta de programação defensiva entre o mundo exterior e o hardware, e então a maioria do seu código dentro das paredes deve ser mais agressiva verificando por erros e gritando com desenvolvedores quando eles fazem a coisa errada.
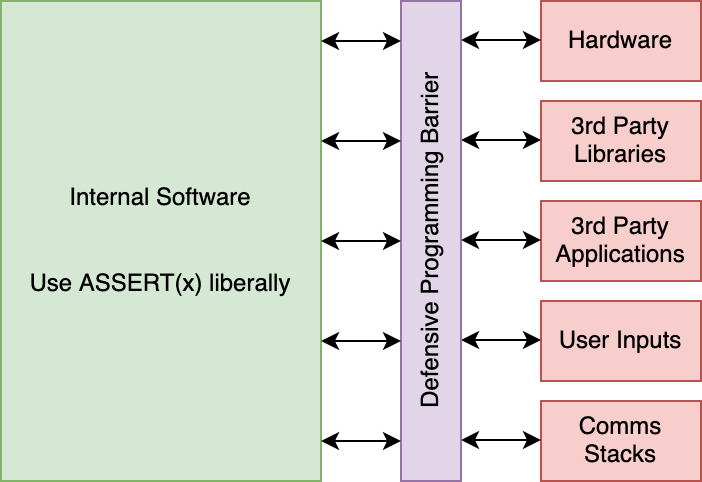 Se os caminhos de código se originam ou passam pelas zonas vermelhas, então a programação defensiva é uma boa abordagem.
Se os caminhos de código se originam ou passam pelas zonas vermelhas, então a programação defensiva é uma boa abordagem.
Por exemplo, vamos supor que temos uma função interna, que leva na sequência que devemos hash e um comprimento. Esta funçãonuncaserá usada diretamente por qualquer consumidores externos, o que deixa apenas desenvolvedores internos.hash32_djb2(const char *str, size_t len)
Tendo um valor de verificação e devolução como o seguinte:
uint32_t hash32_djb2(const char *str, int len)
{
if (str == NULL) {
// Invalid argument
return 0;
}
...
Você só está atirando em si mesmo e seus companheiros desenvolvedores nos pés. Se houver desenvolvedor passa a corda para esta função, ele vai voltar e ser armazenado como um hash válido!NULL0
Argumento thestring é provavelmente o próprio bug do desenvolvedor, e eles devem imediatamente tomar conhecimento do bug, ou então ele pode escorregar em produção.NULL
Essa prática de escrever código para erros de superfície agressivamente é o que é conhecido como Programação “Ofensiva”. (Merriam Webster definição #1, “fazendo ataque”)
Programação Ofensiva
Programação ofensiva, embora aparentemente oposta na escolha da palavra, na verdade expande-se sobre a programação defensiva e leva-o um passo adiante. Em vez de apenas aceitando que pode falhar, software com programação ofensiva em mente pode afirmar que_nunca_falha. Se acall falhar, o software fatalmente afirmar, imprimir informações suficientes para o desenvolvedor torcer causar o problema ou capturar um dump núcleo, e, em seguida, redefini-lo de volta para um conhecido estado de trabalho.malloc()malloc()malloc()
Em sistemas embarcados, onde toda a pilha de hardware para software é muitas vezes construído e controlado por uma única organização, qualquer bug é responsabilidade de os engenheiros dessa organização para criar causa e correção. Programação ofensiva pode ser uma abordagem útil para insetos superficiais que poderiam levar semanas para reproduzir ou nunca ser encontrado.
A programação ofensiva pode tomar muitas formas dentro do software, mas a maioria maneira comum é usarafirmaçõesliberalmente e criativamente contra erros de desenvolvedor e comportamento do estado do sistema.
Vamos passar por algumas situações hipotéticas e como você poderia usar ofensiva programação. Se o sistema incorporado estiver experimentando:
- Problemas de desempenho, como o congelamento da GUI ou tempos de resposta lentos para pressione botão, você pode usarcães de guardaou temporizadores e afirmações para travar o sistema quando o sistema para de modo que um desenvolvedor pode descobrir o que exatamente estava consumindo tempo de CPU.
- Problemas de memória, como alto uso de pilha, sem memória de pilha livre, ou fragmentação excessiva, desencadear uma falha do sistema quando esses estados são detectado e capturar as partes relevantes para análise por um desenvolvedor para descobrir para onde o sistema foi para o lado. Raramente é a chamada final ou a função mais alta na pilha que empurra o sistema sobre a borda, mas tudo o que levou até ele.
malloc() - Problemas de bloqueio- defina um tempo limite de baixa duração (5 segundos) em funções RTOS, tais aand. Definir um tempo limite baixo fará com que o sistema acidente se a operação não teve sucesso no tempo atribuído, novamente permitindo um desenvolvedor para inspecionar ainda mais qual era a questão raiz. Você também pode escolher girar indefinidamente e ter o cão de guardalimpo para cima.
mutex_lockqueue_put
Isso é apenas arranhar a superfície de técnicas de programação ofensiva, mas eu espero que você agora tenha uma ideia do que este artigo é tudo!
Benefícios da Programação Ofensiva
Você pode estar perguntando por que você deve instrumentar o seu código e firmware com um monte de afirmações, temporizadores, cães de guarda, e falhas coordenadas, e isso é um pergunta razoável. Falhas de software em um sistema incorporado não apenas derrubam um segmento, mas muitas vezes todo o sistema também.
Há dois lados desta espada de dois gumes.
Por um lado, quando o dispositivo experimenta problemas imprevistos, você pode deixar o sistema funcionando em um estado indefinido e imprevisível. Talvez o monte está fora de memória, ou o sistema falhou em colocar um evento crítico em uma fila e nós temos dados caíram, ou talvez um segmento tem impasse e não há automatizado mecanismo de recuperação. Alguns dispositivos nem sequer têm botões de energia e precisam ser manualmente desconectado ou as baterias retiradas!
Por outro lado, dispositivos em um estado não intencional são essencialmente dispositivos quebrados e deve ser reiniciado. Se o dispositivo estava fora de pilha, é provável que não vai recuperar e existe um vazamento. Se um fio tem impasse, ele também não vai para se recuperar. Sem mencionar que correr em um estado indefinido deixa o firmware aberto para falhas de segurança e é exatamente o que queremos evitar.
Além de impedir que seu firmware funcionasse em um estado imprevisível, desencadear afirmações e falhas no momento exato do bug ajuda os desenvolvedores rastrear essas questões! Se seus dispositivos estiverem conectados a um depurador enquanto um afirmar ou falha é atingido, ou você tem instrumentação de despejo núcleo, você pode colher o seguintes benefícios:
- Correções mais rápidas de bugs - Se o sistema for interrompido ou um despejo de núcleo for capturado quando uma afirmação é atingida, o desenvolvedor pode ter acesso a backtraces, registros, argumentos de função e estado do sistema, como o heap, listas e filas. Com todas essas informações, os desenvolvedores podem causar problemas mais rapidamente.
- Desenvolvimento mais rápido- Escrever um novo código que se integra vários módulos podem ser complicados se houver bugs ou suposições nos módulos você está se integrando. Por ter afirmações e práticas OffP no camadas circundantes, se um desenvolvedor faz algo desalinhado com a API especificações, o sistema alertará imediatamente o desenvolvedor. É melhor do que. rastreamento de o queormeans e como ele borbulhava através o sistema.
-3unknown_error - Consciência da prevalência - Os desenvolvedores não percebem bugs a menos que sejam óbvio ou caiu em sua caixa de entrada como um relatório de bugs. Forçando o software a reset, a consciência desses bugs desconhecidos é aumentada e os desenvolvedores podem mais facilmente entender quantas vezes eles estão ocorrendo.
- Sistema de retorno ao estado são- Se o seu segmento de comunicados estiver bloqueado, não dados serão enviados de seu dispositivo para o mundo exterior, tornando seu dispositivo um tijolo até que um usuário o reinicie manualmente. Ao redefinir o dispositivo, você está mais propensos a colocar o dispositivo de volta em um estado de funcionamento. A maioria dos dispositivos incorporados tem tempos de reinicialização muito rápidos, por isso não é um grande negócio.
Programação Ofensiva na Prática
Vamos cavar em alguns exemplos concretos de bugs que podemos encontrar usando ofensivo práticas de programação.
Validação de argumentos
Se um desenvolvedor tentar usar uma API e passar argumentos inválidos para o função, certifique-se de que o aplicativo grita com eles para corrigir o problema. Há nada pior do que receber valor areturn e cavar através de 10 camadas de código de firmware apenas para descobrir a verdadeira razão foi que você passou em um sequência de 20 caracteres quando o máximo era 16 ou porque você acidentalmente passou um ponteiro nulo devido a uma variável nãonitializada.-1
void device_set_name(char *name, size_t name_len) {
ASSERT(name && name_len <= 16);
...
}
A única vez que eu escolheria, ou pelo menos fortemente debater, para não usar afirmações para validar argumentos é quando eu estou construindo uma biblioteca que será usado por pessoas fora da minha organização. Nesses casos, eu faria a validação afirma opcional, assim como o FreeRTOS faz com suas funções RTOS, permitindo que os desenvolvedores para definir-los1.configASSERT
Esgotamento de recursos
Embora o uso de memória dinâmica em sistemas incorporados às vezes seja desaprovada, ela é muitas vezes necessário para sistemas complexos que não têm memória estática suficiente para circular. Mesmo quando a memória dinâmica é usada, ficar sem memória raramente deve acontecer. Quando a memória está baixa, os sistemas devem se adaptar e colocar de volta a pressão em qualquer dados fluindo para o sistema e taxas de limitação de memória-intensiva operações.
No entanto, se um_firmware_esgotar o pool de memória dinâmica, queremos saber quando e por que aconteceu! Pode ser um vazamento de memória ou uma alocação acidental que consumiu a maior parte do monte. Ficar sem memória pode não ser um mostrar-parar questão, porque o sistema_pode_se recuperar, mas se estamos no desenvolvimento ou fase de testes internos, vamos descobrir por que acabou!
Para fazer isso, podemos adicionar uma afirmação dentro da função que verifica que a chamada não falhou.malloc()
void *malloc_assert(size_t n) {
void *p = malloc(n)
ASSERT(p);
return p;
...
}
Em código onde as chamadas nunca deve falhar, como para o alocação de primitivos RTOS, buffers de solicitação e resposta, etc., podemos usar esta versão afirmada.malloc()
Outro problema comum com sistemas baseados em RTOS é uma fila se tornando cheia devido a não sendo processado rapidamente o suficiente. Como com o esgotamento da memória, este não é um mostrar-parar questão, porque o sistema pode se recuperar, mas poderíamos muito bem ser soltando eventos que são críticos para o funcionamento do dispositivo! Este é um questão que deve ser investigada e idealmente evitar que aconteça.
Podemos adicionar anpara confirmar que cada inserção de fila foi bem sucedida, ou talvez até mesmo embrulhar essa função se quisermos.ASSERT()
void critical_event(void) {
...
const bool success = xQueueSend(q, &item, 1000 /* wait 1s */)
ASSERT(success);
...
}
Para ajudar com o processo de depuração de uma fila cheia, sugiro muito escrever umPython GDB scriptpara despejar o conteúdo da fila. Então, quando o sistema é parado ou você tem um dump núcleo permitindo que você descubra quais eventos estavam consumindo a maioria dos o espaço na fila!
(gdb) queue_print s_event_queue
Queue Status: 10/10 events in queue (FULL!)
0: Addr: 0x200070c0, event: BLE_PACKET
1: Addr: 0x200070a8, event: TICK_EVENT
2: Addr: 0x20007088, event: BLE_PACKET
3: Addr: 0x20007070, event: BLE_PACKET
4: Addr: 0x20007050, event: BLE_PACKET
5: Addr: 0x20007038, event: BLE_PACKET
6: Addr: 0x20007018, event: BLE_PACKET
7: Addr: 0x20007000, event: BLE_PACKET
8: Addr: 0x20006fe0, event: BLE_PACKET
9: Addr: 0x20006fc8, event: BLE_PACKET
Parece que nossa fila estava cheia de pacotes de nossas massas de comunicados e não estávamos processá-los rapidamente o suficiente. Agora sabemos onde está o problema e podemos encontrar um solução.
Software Stalls & Deadlocks
Dispositivos incorporados precisam responder em uma quantidade razoável de tempo à entrada do usuário e pacotes de comunicação tudo isso enquanto é realizador e não mostrando nenhum sinal de lag ou barracas.
Eu não posso contar o número de vezes enquanto trabalha em projetos anteriores que diminuem operações flash fez com que o sistema congelasse por 2-3 segundos de cada vez, causando estragos na experiência do usuário ou causando outras operações no sistema ao tempo fora. A pior parte sobre essas questões é que muitas vezes eles não são trazidos para atenção dos desenvolvedores até que seja tarde demais.
Para ajudar a pegar esses problemas antes de empurrar o firmware para usuários externos, você pode criar e configurar suatarefa cães de guardapara ser mais agressivo, configurar temporizadores para afirmar depois de alguns segundos durante operações potencialmente longas, e certifique-se de definir tempo limite em sua rosca chamadas do sistema.
Para afirmar que um mutex foi bloqueado com sucesso, podemos passar um tempo limite para a maioria RTOS liga e afirma que conseguiu.
void timing_sensitive_task(void) {
// Task watchdog will assert a stall
const bool success = mutex_lock(&s_mutex, 1000 /* 1 second */);
ASSERT(success);
{
...
}
}
Ou, se umatarefa cão de guardaé configurado para detectar baias, você pode apenas esperar indefinidamente!
void timing_sensitive_task(void) {
// Task watchdog will assert a stall
mutex_lock(&s_mutex, INFINITY);
{
...
}
}
Uma vez que um soluço e parar aqui e não há o fim do mundo, quando você construir a imagem final que você vai empurrar para os clientes, você pode sintonizar ou (suspiro!) remover esses cheques completamente.
Use depois de bugs gratuitos
Depois de um buffer alocado comis’ed, ele nunca deve ser usado novamente por software. No entanto, isso acontece o tempo todo. Este bug é apropriadamente chamado de um Bug “Use depois de livre”2. Se o sistema reutilizar um buffer que foi libertado, há uma boa chance de nada de ruim acontecer. O sistema será feliz usar o buffer e escrever e ler dados dele.malloc()free()
No entanto, às vezes, resultará em corrupção de memória e se apresentar em as maneiras mais estranhas. Bugs de corrupção de memória são notoriamente difíceis de depurar.
Se você está lutando com problemas de corrupção de memória, você pode querer leresta seção sobre a captura de corrupção de memória bugsde um post anterior.
Uma maneira de ajudar a prevenir bugs pós-uso é esfregar todo o conteúdo de a memória com um endereço inválido que, quando acessado, causaria umHardFaultem nosso Cortex-M4 e em última análise, parar o sistema ou capturar um despejo de núcleo.
void my_free(void *p) {
const size_t num_bytes = prv_get_size(p);
// Set each word to 0xbdbdbdbd
memset(p, 0xbd, num_bytes);
free(p);
}
Ao inspecionar o despejo principal, os backtraces e o conteúdo tampão mostrariam o nosso endereço ruim e nós imediatamente sabemos que era um “uso depois bug livre “.0xbdbdbdbd
Erros de transição do Estado
Estou assumindo que a maioria dos geradores de máquinas estaduais ou melhores práticas impedem o estado erros de transição de acontecer para começar, mas se esse não é o caso, este um é importante e vale a pena colocar em suas máquinas de estado.
Vamos fingir que temos dois estados, e, onde o compromisso acontece depois e somente depois de um estado de descarga. Podemos afirmar isso mudança de estado em nossa função como uma verificação de sanidade.kState_FlushingkState_Committing
void on_commit(eState prev_state) {
ASSERT(prev_state == kState_Flushing);
}
Erros do programador de tempo de compilação
Desenvolvedores cometem erros o tempo todo. Uma defesa que podemos colocar em prática contra nós mesmos é usando3. Eu geralmente uso isso é para certifique-se de que minhas estruturas não excedam um limite de tamanho necessário.static_assert
typedef struct {
uint32_t count;
uint8_t buf[12];
uint8_t new_value; // New field
} MyStruct;
_Static_assert(sizeof(MyStruct) <= 16, "Oops, too large!");
Quando tento compilar isso, recebo um erro de tempo de compilação:
$ gcc test.c
test.c:14:1: error: static_assert failed due to requirement
'sizeof(MyStruct) <= 16' "Oops, too large!"
_Static_assert(sizeof(MyStruct) <= 16, "Oops, too large!");
^ ~~~~~~~~~~~~~~~~~~~~~~
1 error generated.
Você pode usar isso em qualquer coisa que possa ser definida estaticamente, incluindo alinhamento de campos de estrutura, tamanhos de estrutura e enum, e comprimentos de cordas. Engraçado o suficiente, eu. também usar isso quando eu quero forçar a mim mesmo e outros a pensar duas vezes sobre certas mudanças. Se eu quisesse ter certeza de que eu ou qualquer outra pessoa
_Static_assert(sizeof(MyStruct) == 16,
"You are changing the size! "
"Please refer to https://wiki.mycompany.com/... "
"to learn how to update the protocol version ...");
Felizmente, essas cordas não são incluídas no binário de firmware final para que você são livres para fazê-los o tempo que você quiser!
Manipulação do Código Externo & De Aplicativos
Há lugares onde não se gostaria de usar programação ofensiva Práticas. Principalmente, é quando o desenvolvedor não está totalmente no controle do software, hardware ou dados recebidos. Estes podem ser qualquer um dos seguintes:
- Drivers de hardware e periféricos
- Conteúdo de armazenamento flash ou persistente
- Bibliotecas HAL ou 3ª parte
- Dados ou entradas externas de pilhas de comms
- Intérpretes de idiomas, como MicroPython4ou JerryScript5
- Aplicativos de terceiros escritos por desenvolvedores externos
Todas essas variáveis ou entradas estão fora do controle do desenvolvedor, e você não deve confiar em nenhum deles! Os desenvolvedores farão o mais criativo, coisas bonitas, terríveis, abusivas e perigosas para sua plataforma, não intencional ou não, e você deve ser muito cauteloso com isso.
Para evitar que os insetos pisem no seu gramado, você pode isolar essas camadas externas com uma camada de calço que usa programação defensiva. Isso garante que qualquer ruim entradas, dados corrompidos e atores nefastos recebem códigos de erro em vez de quebrando o software.
Uma coisa importante, que não pode ser estressado o suficiente, é que você pode quase sempre confiar e assumir que desenvolvedores e código interno para sua organização ou projeto será correto ou pelo menos_quer_estar correto. Com isso em mente, podemos afirmar tudo dentro do blocode Software Internoe travar o aplicativo ou sistema e fornecer dados úteis para desenvolvedores internos.
Melhores Práticas
Não afirme em sequências de inicialização
Simples e doce. Não afirme nada sobre o código que é executado durante um boot-up sequência que não é garantido, porque é assim que loops de reinicialização podem ocorrer quando algo dá errado. A única vez que eu iria afirmar em uma sequência de inicialização é quando o meu dispositivo está conectado a um depurador, ou quando as coisas são absolutamente necessárias e não há nenhuma chance de enviar um firmware quebrado para usuários finais.
Em caso de dúvida, registre esses erros em vez disso.
Jogando ataque internamente
Não há melhor momento para permitir afirmações, cães de guarda e outras práticas OffP do que quando um conselho de desenvolvimento está conectado a um depurador! Com isso no lugar, desenvolvedores podem instantaneamente e facilmente obter backtraces e estado do sistema, bem como rastreamento através da execução do comportamento indefinido para descobrir o que aconteceu bem como potencialmente descobrir o que_aconteceria_se o bug não fosse corrigido.
Jogando Ataque em Construção de Produção
Antes de investigar quais aspectos do OffP fazem sentido nas construções de produção, precisamos para estabelecer que acidentes de software devem ser registrados de alguma forma para que um desenvolvedor pode recuperá-los em uma data posterior. Isso pode ser alguma forma de registro, rastreamento, ou lixões principais, ou qualquer combinação destes. Se não temos uma maneira de problemas de registro, nunca saberemos o que realmente causa essas questões e com que frequência eles ocorrem.
As partes do OffP que devem ser mantidas compiladas e habilitadas na produção construções são as que garantem que o comportamento indefinido não é experimentado em firmware. Isso inclui validação de argumentos, tempo limite para detectar impasses, bugs potencialmente levando à corrupção da memória, etc. É melhor. devolver o dispositivo para um estado conhecido do que mancar junto.
O que podemos muitas vezes considerar desativar completamente são questões marginais, como baias de software, falhas de malloc e fila (que são manuseadas) e tempo limite. Esses tipos de problemas não são garantidos para recuperar ou ir embora, mas eles podem ser aceitável dependendo do contexto e de como o dispositivo é usado.
Se você optar por reduzir a agressividade dos cheques, considere manter o ganchos e tempo limite e, em vez disso, registrá-los em algum lugar, em vez de redefinir o sistema. Para se inspirar, confira aAPI de manipulação de erros da ARM MBed, que mantém um buffer circular de avisos que o sistema experimentou em um região de RAM que é mantida entre reinicializações. A ideia é que todas as camadas do firmware usar uma API de erro único e, em seguida, os desenvolvedores podem fazer o que quiserem com eles. Se você tiver infraestrutura de registro no local, você pode registrá-los no boot, ou se o seu sistema estiver configurado com lixões principais, você pode capturar esta região de memória também.
Por exemplo, podemos modificar o ourmacro para, em vez disso, registrar através do sistema de registro em vez de desencadear um reset quando uma compilação de produção é compilado.ASSERT()
#if PRODUCTION_BUILD
#define MY_ASSERT(expr, msg) \
do { \
if (!(expr)) { \
/* log error to buffer */ \
} \
} while (0)
#else
#define MY_ASSERT(expr, msg) \
do { \
if (!(expr)) { \
/* core dump */ \
} \
} while (0)
#endif
Conclusão
Adoro quando meu firmware e ferramentas funcionam comigo em vez de contra mim. Se o firmware sabe que há um problema, ele deve fazer esse fato frente e centro e talvez até me apontar para uma página da Wiki explicando o que eu fiz de errado! Isto é o que programação ofensiva é tudo sobre. Se você implementar essas ideias em seu firmware, mesmo que apenas alguns deles, eu prometo que eles vão pagar dividendos e você será capaz de causar problemas mais rapidamente do que antes.
Eu adoraria ouvir sobre quaisquer outras estratégias que todos vocês levam para insetos à superfície que estão escondidos em seu firmware! Venha me encontrar noInterrupt Slack.
Interessado em aprender mais práticas de programação ofensiva e defensiva? Inscreva-seno nosso webinar na Febraury 24, 2022.
Como interromper? Inscreva-separa obter nossas últimas postagens diretamente em sua caixa de correio.
Vê alguma coisa que gostaria de mudar? Envie uma solicitação de retirada ou abra um problema noGitHub
Referências
- FreeRTOS - xTaskCreateStatic ↩
- CWE-416: Use depois de grátis↩
- static_assert - CppReference ↩
- MicroPython ↩
- JerryScript ↩