Julia - uma linguagem para o futuro da cibersegurança
Julia 1.0 foi lançado em 2018. É uma linguagem criada para ter tanto a simplicidade de alto nível como Python, mas desempenho de baixo nível como C. Neste tutorial vamos fazer uma codificação legal com ele…
Julia é uma linguagem comparativamente nova que visava ter o desempenho de C e simplicidade de Python. Tendo a capacidade de realizar análise de dados sem muitos problemas enquanto envia o código com desempenho competitivo, espera-se que Julia seja uma ferramenta poderosa nos negóciosda FinTech. Mas eu acho que também tem alguns grandes potenciais em relação às tendências atuais emCibersegurança.
Neste artigo, explicarei por que Julia também pode ser uma ótima ferramenta para o futuro daCibersegurança. Enquanto isso, compartilharei como escrevi um roteiro da Julia no meu computadorMacpara decifrar um texto cifrado criptografado como Caesar Code Shiftea Columnar Transposition. No final, vou compartilhar algumas comparações de desempenho e o código para este projeto no apêndice.
Primeiro vamos rever alguns dos fundamentos em segurança cibernética. Como criptografamos nossas mensagens e autenticamos usuários. Vamos passar por cima do antigo turno de código Caesar e transposição colunar, que estão envolvidos no exemplo do código. E então, vamos passar por cima da autenticação biométrica e por que Julia pode ser uma grande ferramenta para o futuro da cibersegurança.
Como humanos nos comunicamos uns com os outros, mas às vezes não queremos que todos saibam sobre o que estamos nos comunicando. Desde a Roma Antiga, Júlio Césartem enviado mensagens militares secretas mudando cartas de código na mensagem. Por exemplo, “A” será transferido para “B” e “Z” será transferido para “A”. A palavra “HAL” será transferida para “IBM”. A técnica foi mais tarde nomeada em homenagem a ele, conhecido comoa Cipher César.
Havia uma enorme vulnerabilidade a essa criptografia baseada em mudança de código. Durante o início da Segunda Guerra Mundial, os matemáticos analisaram a frequência de ocorrência de cada alfabeto na Alemanha. Comparando os gráficos de barras de frequência, eles foram capazes de descobrir a mudança. A história se estende a como os alemães então inventaram oEnigma, e como Alan Turing conseguiu decifrá-lo com sua gigantesca máquina de computação.
Havia muitas outras técnicas que usamos para criptografar nossas mensagens. Outra é atransposição colunaar. O que envolve colocar o texto em uma tabela, em seguida, reorganizar as colunas e ler o texto de volta.
Outros métodos de criptografia, como RSA,ECC eMD5, são amplamente utilizados no envio de informações com segurança pela internet. RSA, por exemplo, é umaCriptografia Assimétricaque aproveita as propriedades dosnúmeros primos.
Como o crescente envolvimento da ciência de dados e inteligência artificial em cibersegurança, que também requer um bom desempenho em suas aplicações relacionadas, Julia definitivamente passa a ser um ajuste útil. Quer se inclinar sobre como funciona? Vamos passar por cima de um exemplo imediatamente!
Cracking Caesar Code Shift e Columnar Transposição com Julia
KUHPVIBQKVOSHWHXBPOFUXHRPVLLDWVOSKWPREDDVVIDWQRBHBGLBBPKQUNRVOHQEIRLWOKKRDD
Pediram-me para decifrar o texto da cifra acima. A dica era que era cifrado comCaesar Code ShifteColumnar Transpositioncom um comprimento de chave menor que 10. Decifrar essas mensagens secretas geralmente envolve algum tipo de abordagem de força bruta, que pode ser computacionalmente cara. Para reduzir um pouco de sua complexidade, também é necessária colisão com dicionários.
Para ser rápido, a primeira coisa que me veio à mente foiC. Mas esses cabeçalhos e gerenciamento de memória podem ser uma dor para lidar. Python, por outro lado, é apoiado por bibliotecas poderosas e gramática minimalista, mas sacrifica muita velocidade. Depois de algumas considerações, acabo fazendo isso comJulia.
1. Começar
Agora vamos começar!
Primeiro, teremos que baixar Julia, umaversão macdo download pode ser encontradaaqui. Você também pode visitar a página oficial dedownloadpara outras versões e informações.
Após o download, podemos abrir oconsole da linha de comandoclicando duas vezes no ícone do aplicativo.
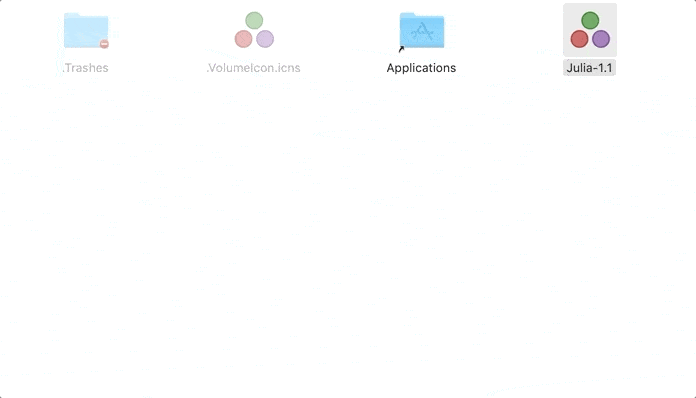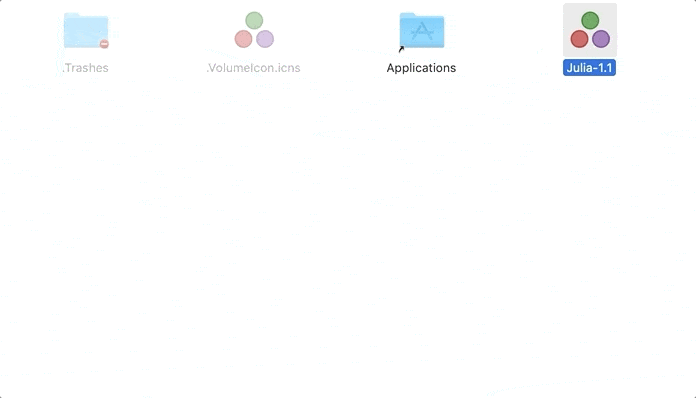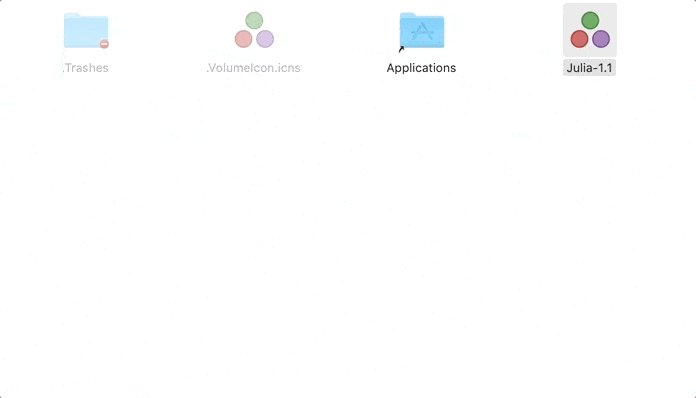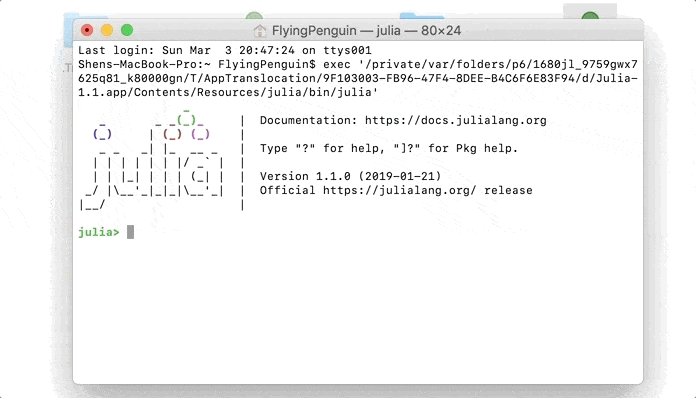
Para executar quaisquer scripts salvos como arquivo local, podemos usar o comandoinclude()dentro doconsole da linha de comando:
include("<PATH_TO_YOUR_JULIA_SCRIPT>/hello_world.jl")
The name of the file has the extension .jl.
Agora, para concluir este projeto, também precisaremosimportardois pacotes:
- ACombinatoricsque precisaremos para gerar a permutação para a transposição colunaar
- OProgressMeterque precisaremos para mostrar o progresso decifrante.
Podemos fazer isso com os seguintes comandos.
Instalação deCombinatorics:
#import Pkg; Pkg.add("Combinatorics")
Installing ProgressMeter:
import Pkg; Pkg.add("ProgressMeter")
Também precisamos de um arquivo de dicionário que possa ser baixadoa partir daqui. O dicionário contém palavras em inglês comumente usadas que podemos usar no futuro para colidir com nosso texto cifrado.
2. Importação de texto cifrado e frequência de palavras em inglês
Podemosdefinir uma sequênciaem Julia como em qualquer outro idioma, e não precisamos especificar o tipo. A funçãoprintln()imprime a string em uma nova linha como muitas outras línguas, como Java. As cordas sãoconcatenadascom umacíriaem vez de um símbolo positivo.
cipherText = “KUHPVIBQKVOSHWHXBPOFUXHRPVLLDWVOSKWPREDDVVVIDWQRBHBBLBLBBPKQUNRVOHQEIRLWOKKRDD”
.println(“Comece a descriptografar texto cifrado: “, cipherText)
Cada carta ocorre em frequência diferente em inglês, onde uma lista pode ser encontradaaqui. Diferentes fontes podem ter estatísticas ligeiramente diferentes. Podemos definir uma lista de pontos flutuantes em Julia com o seguinte comando.
println("Initializing frequency array for ENGLISH...")
ENGLISH = [0.0749, 0.0129, 0.0354, 0.0362, 0.1400, 0.0218, 0.0174, 0.0422, 0.0665, 0.0027, 0.0047, 0.0357,
0.0339, 0.0674, 0.0737, 0.0243, 0.0026, 0.0614, 0.0695, 0.0985, 0.0300, 0.0116, 0.0169, 0.0028,
0.0164, 0.0004]
Agora gostaríamos de contar cada uma das letras, então temos que criar uma lista de zeros com o mesmo tamanho que há alfabetos em inglês. Podemos fazer isso com os seguintes comandos. O comprimento das listas pode ser recuperado comcomprimento(). Podemos lançar um personagem para inteiro comInt(). Os valores podem ser incrementados com um operador ”+=”. Um loop em Julia parece o seguinte:
contagens = zeros (comprimento(INGLÊS))
para letra no código cifradotexto
= Int(letter) - Int(‘A’)
se o código < 1
código += 26
contagens finais
[código] += 1
extremidade
Fazemos tantas mudanças quanto alfabetos na língua inglesa, totalizando 26 turnos, incluindo sem turnos. Podemos fazê-lo com a funçãocircshift().
variâncias = zeros (comprimento(INGLÊS))
para mudança em 0:length(INGLÊS) - 1
println (“Aplicando mudança de césar inverso: “, shift)
shiftedCounts = circshift(counts, -1 * shift)
variance = soma (transmissão(abs, (((shiftedCounts / comprimento (cipherText) - INGLÊS) / INGLÊS))
variâncias[shift + 1] = variância;
println final
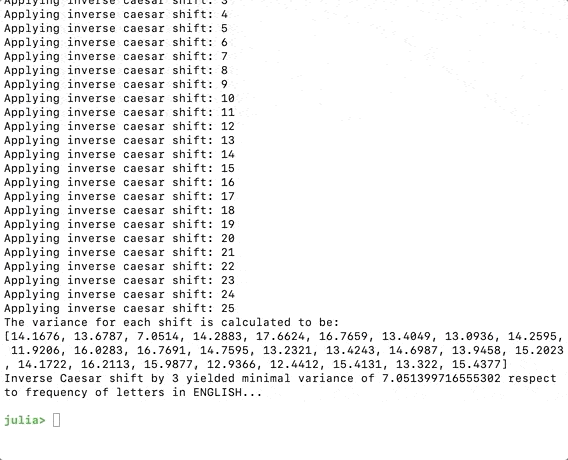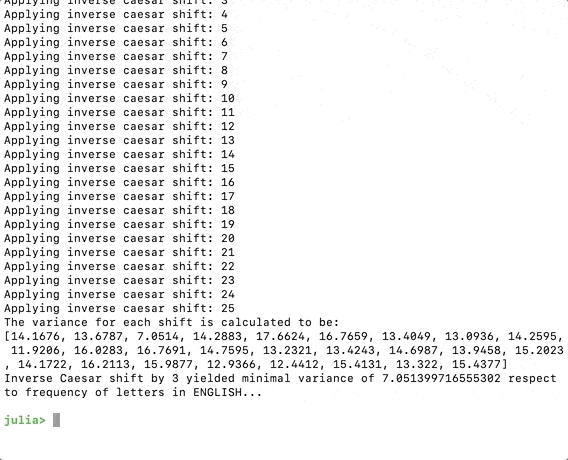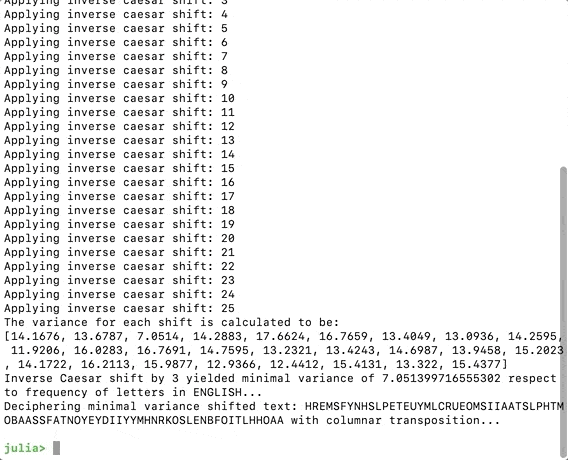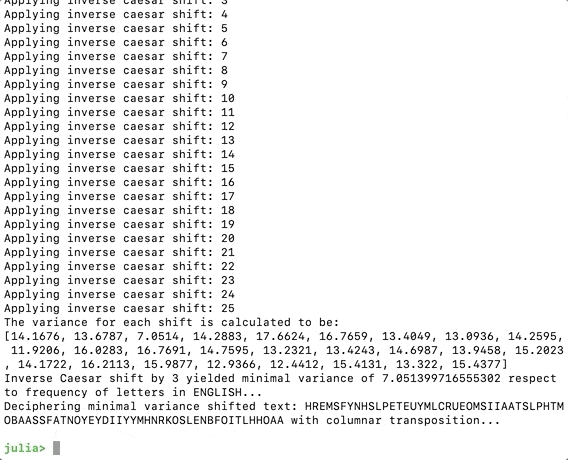
(“A variância para cada turno é calculada como: \n”, variâncias)
minshift = argmin(variâncias)
Dentro do loop for calculamos a diferença entre as frequências contadas e suas frequências em palavras em inglês para cada alfabeto. Subtrações e divisões podem ser feitas diretamente no nível da lista. Oboardcast de função()mapeia a funçãoabs()para cada elemento dentro da lista semelhante aoSchemeouJava Script. Asoma()função encontra a soma total da lista. A variância de cada letra é dividida por suas frequências em inglês para que a variância não seja influenciada pela frequência da letra.
variance = sum(broadcast(abs, ((counts / length(cipherText) - ENGLISH) / ENGLISH)))
As operações da lista funcionam semelhantes àspython, enquanto ”.*“é usada para multiplicação. Recursos como subtração de um inteiro de uma matriz ainda não são suportados. Mais informações podem ser encontradas nadocumentação oficial.


Agora, se executarmos o código, devemos obter o seguinte, o programa imaginou que amudança mais plausível é 3.
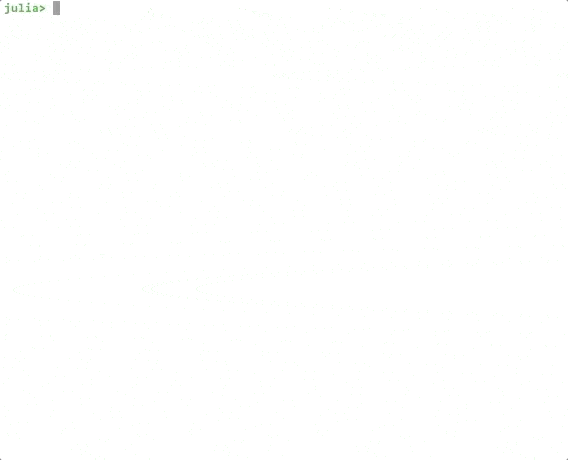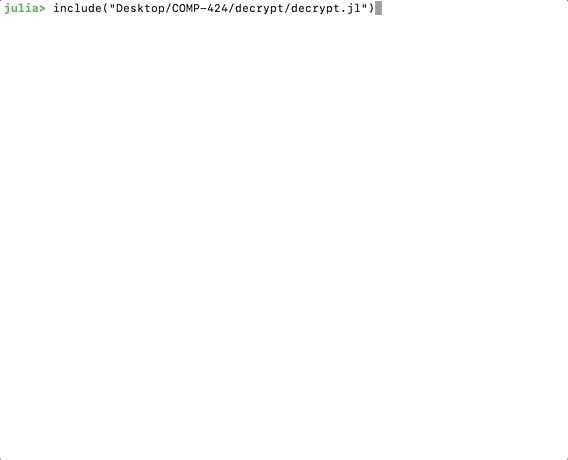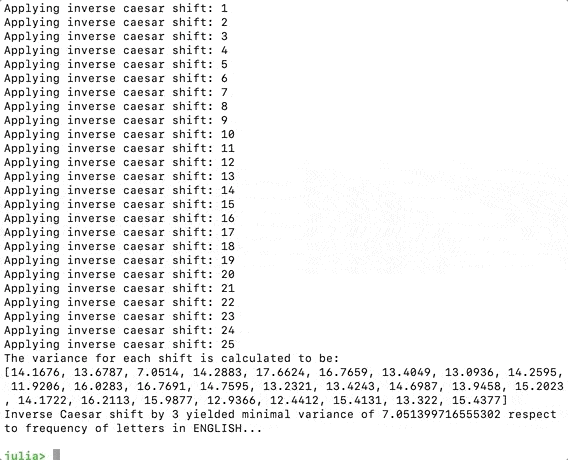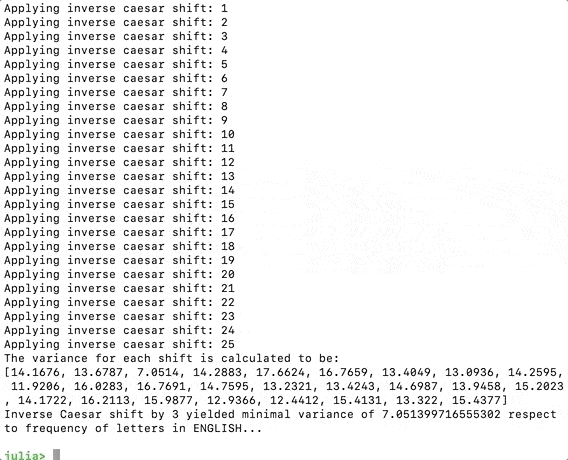

Agora podemos imprimir a sequência deslocada com os seguintes scripts. A funçãoChar()lança o código inteiro de volta para um personagem, oapêndice!() função anexa o caractere à lista, e a funçãojoin()junta alista de caracteresem umasequência.
shiftedTextList = []
para letra no código CipherText
= Int(letter) - minshift
se o código < código Int(‘A’)
+= 26
apêndice final
!( shiftedTextList, Char(code))
end
shiftedText = join(shiftedTextList)
println(“Decifrando texto de variação mínima: “, shiftedText” com transposição colunaar…”)

3. Aplicação de transposição de colunaar e colisão de dicionário utilizante
Primeiro, temos que referenciar os pacotes necessários que instalamos nas seções anteriores, podemos fazê-lo com os seguintes códigos. Essas declarações podem ser colocadas em qualquer lugar antes de serem usadas em vez de ter que estar no topo do seu código.
usando Combinatorics
usando o ProgressMeter
E então podemos importar nosso dicionário com o seguinte código.
filename = "<PATH_TO_YOUR_DICTIONARY_FILE>/google-10000-english.txt"
println("Loading common words DICTIONARY from: ", filename)
DICTIONARY = readlines(filename)
This should print a snippet of the dictionary after we save and run the code.
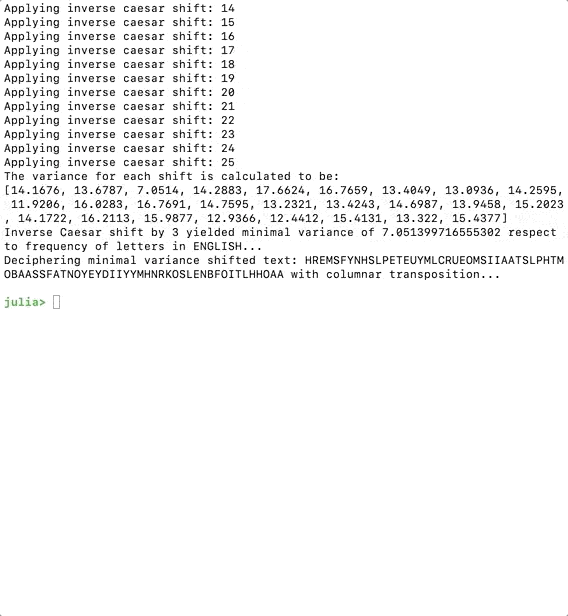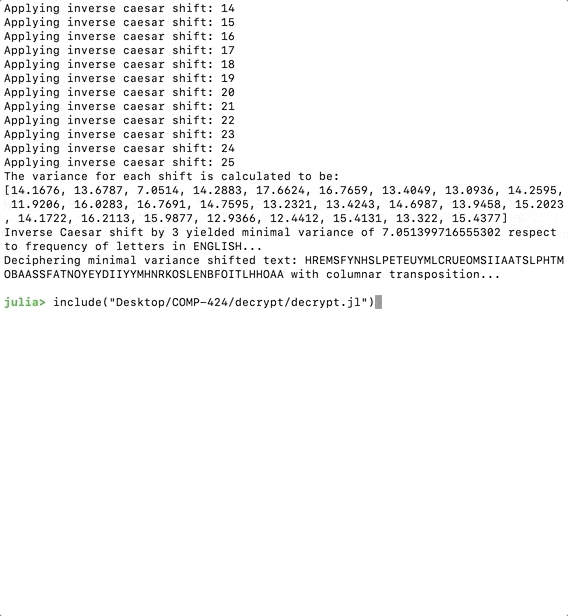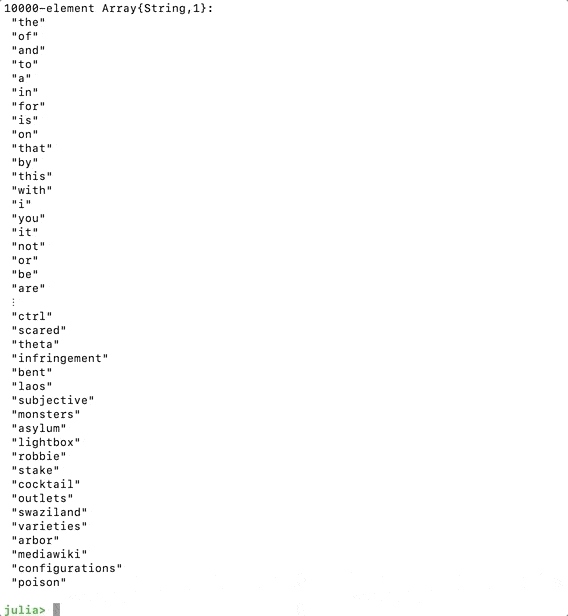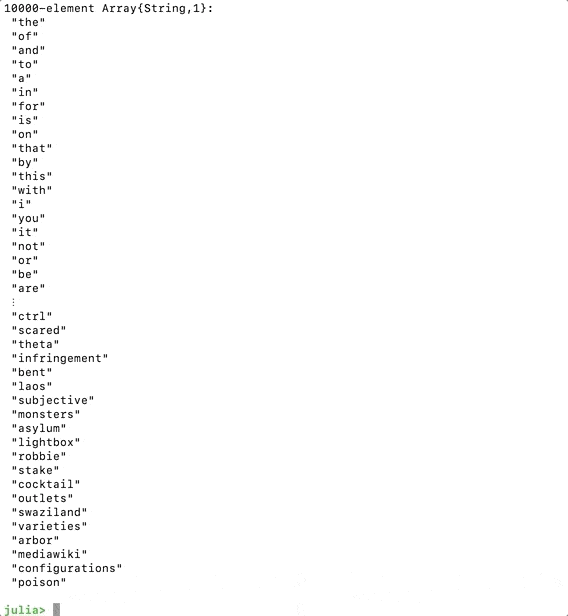

Agora queremosconstruir a matriz da colunaeiterar através de cada uma das permutações. O código a seguir fará o trabalho.
para largura em 2:3
println (“Aplicando transposição colunar com largura: “, largura)
matriz = []
altura = Int(ceil(comprimento(shiftedText) / largura)total
= largura * altura
para índice em 1:total
se índice <= comprimento (shiftedText)
apêndice!( matriz, shiftedText[índice])
outro
apêndice!( matriz, “?”)
matriz final
= remodele(matriz, (altura, largura))
ordens = coletar(coletar(coletar(1:largura)))
println(matrix)
println(orders)
end
A funçãoceil()arredondao número para o inteiro mais próximo. Preenchemos os espaços em branco com”?”. A funçãoremodele()molda a matrizpara asdimensões especificadas. Geramos as ordens compermutações(), que pega uma lista de elementos como entrada e retorna todas as permutações possíveis. A entrada é gerada comcoleta (1:largura), onde a coleta converte a faixa “1:largura” em uma coleção, ou seja, uma lista.
Agora, depoisde salvar e recarregar, devemos ver as mesas colunares reconstruídas impressas com as permutações. Ponto e vírgulaindica umanova linha.


Antes de passarmos pelas permutações, devemos mostrar umabarra de progresso, pois a tarefa vai levar algum tempo. Não queremos sentar e nos perguntar se o programa ainda está em execução ou não. Com os pacotes que importamos, o seguinte códigoantes do loopinicializará a barra de progresso.
n = comprimento (ordens)
p = Progresso(n, 1, “Computação todas as permutações:”, 50, :preto)
E colocamos isso no final do loop paraatualizara barra de progresso. Para obter mais informações sobre como usar oProgressMeter, dê uma olhadaaqui.
próximo! (p)
O código completo para colisão de dicionário pode ser encontrado abaixo. Onde ele usamaiúsculas para capitalizar as palavras no dicionário, e ocorre()para ver se ele aparece no texto rearranjado. Uma vez que as palavras comuns contribuíram para uma quantidade significativa do texto rearranjado, ele as imprime e mantém o controle da permutação que produz a maior porcentagem de palavras comuns.
completed = 0
n = length(orders)
p = Progress(n, 1, "Computing all permutations:", 50, :black)
bestPlainText = "?"
bestPlainTextCommonPercentage = 0
for permutation in orders
plainTextMatrix = []
for row in 1:height
for columnIndex in 1:width
char = matrix[row, permutation[columnIndex]]
if char != '?'
append!(plainTextMatrix, char)
end
end
end
plainText = join(plainTextMatrix)
wordCount = 0
wordLengthSum = 0
words = []
for word in DICTIONARY
if length(uppercase(word)) > 3 && occursin(uppercase(word), plainText)
wordCount += 1;
wordLengthSum += length(word)
push!(words, uppercase(word))
end
end
percentageCommon = wordLengthSum / length(plainText) * 100
if percentageCommon > 50
println("\rColumnar transposition with the order of: ", permutation, " yielded a string containing ", wordCount, " common word(s) which makes it ", percentageCommon, "% common words, below is the string:\n", plainText, "\ncontaining the words:\n", words)
if percentageCommon > bestPlainTextCommonPercentage
bestPlainText = plainText
bestPlainTextCommonPercentage = percentageCommon
end
println("Currently, the best plain text is:\n", bestPlainText, " which is ", bestPlainTextCommonPercentage, "% common words...")
end
next!(p)
end
Este algoritmo não é perfeito, onde a porcentagem tem o potencial de passar de 100% se houver palavras sobrepostas. Torná-lo perfeito requer um pouco de trabalho demais, pois você tem que considerar todas as palavras permutações, então vamos ficar com o caminho rápido e sujo por enquanto. A porcentagem também está aqui apenas para a referência.
Antes de irmos para o teste, também temos queaumentar a largura máximada tabela para 10, pois sabemos que para ser o comprimento máximo da chave de nossas dicas.
Nós mudamos:
for width in 2:3
into:
for width in 2:10
E devemos remover o seguinte código de teste que tínhamos antes:
println(matrix)
println(orders)
Agora devemos ser capazes de salvar e lançar o código.

E depois de algum tempo, devemos ver o texto simples sendo impresso, pois tem a maior porcentagem de palavras comuns. O texto é decifrado para ser:
BEHAPPYFORTHEMOMENTTHISMOMENTISYOURLIFEBYKHAYYAMOHANDALSOTHISCLASSISREALLYFUN

Parabéns!!! Você acabou de aprender a escrever um biscoito de texto cifrado em Julia! Espero que este seja um grande começo de sua exploração na língua.
No final…
Julia é uma linguagem simples e poderosa na análise de dados. Você pode ler mais sobre seu desempenho nos links abaixo:
Julia is a simple and powerful language in data analysis. You can read more about its performance from the links below:
- Comparação Básica de Python, Julia, Matlab, IDL e Java (Edição 2018)
- Comparação Básica de Python, Julia, R, Matlab e IDL
- Uma comparação de velocidade de C, Julia, Python, Numba e Cython na Fatorização LU
Você verá que o desempenho deJuliavai muito à frente sobrePythonpara tamanhos de entrada maiores, e até superaCpara cálculos de matriz. Cálculos de matriz são amplamente utilizados em aprendizado de máquina e ciência de dados, e o tamanho da entrada geralmente pode se tornar muito grande.
Sou um codificador apaixonado que adora aprender coisas novas e compartilhá-la com a comunidade. Se houver algo em particular que gostaria de ler, por favor, me avise. Eu me concentro principalmente emInteligência Artificial, Interações humanas de computadorerobóticaagora, mas há muitas coisas sobre as quais posso escrever.
Posso continuar escrevendo sobreJuliae talvez um pouco sobreCiência de Dados. Muitos dos meus trabalhos de pesquisa são confidenciais, mas uma vez que eles são liberados, eu terei muito para compartilhar. Eu também posso recriarmodelos de ciência de dadosemJulia, assim como eu codificei umaRede Neural ArtificialemUnity C#antes que seus módulos de aprendizado de máquina sejam bem construídos. Espero que você tenha gostado de aprender essas coisas novas e legais tanto quanto eu!
Eu anexei o código completo deste projeto ao apêndice.
Apêndice (Código Completo deste Projeto):
cipherText = "KUHPVIBQKVOSHWHXBPOFUXHRPVLLDDWVOSKWPREDDVVIDWQRBHBGLLBBPKQUNRVOHQEIRLWOKKRDD"
println("Begin to decrypt cipher text: ", cipherText)
#https://en.wikipedia.org/wiki/Letter_frequency
frequencies = Dict( "A" => 8.167,
"B" => 1.492,
"C" => 2.782,
"D" => 4.253,
"E" => 12.702,
"F" => 2.228,
"G" => 2.015,
"H" => 6.094,
"I" => 6.966,
"J" => 0.153,
"K" => 0.772,
"L" => 4.025,
"M" => 2.406,
"N" => 6.749,
"O" => 7.507,
"P" => 1.929,
"Q" => 0.095,
"R" => 5.987,
"S" => 6.327,
"T" => 9.056,
"U" => 2.758,
"V" => 0.978,
"W" => 2.360,
"X" => 0.150,
"Y" => 1.974,
"Z" => 0.074)
#https://code.activestate.com/recipes/142813-deciphering-caesar-code/
println("Initializing frequency array for ENGLISH...")
ENGLISH = [0.0749, 0.0129, 0.0354, 0.0362, 0.1400, 0.0218, 0.0174, 0.0422, 0.0665, 0.0027, 0.0047, 0.0357,
0.0339, 0.0674, 0.0737, 0.0243, 0.0026, 0.0614, 0.0695, 0.0985, 0.0300, 0.0116, 0.0169, 0.0028,
0.0164, 0.0004]
variances = zeros(length(ENGLISH))
counts = zeros(length(ENGLISH))
for letter in cipherText
code = Int(letter) - Int('A')
if code < 1
code += 26
end
counts[code] += 1
end
for shift in 0:length(ENGLISH) - 1
println("Applying inverse caesar shift: ", shift)
shiftedCounts = circshift(counts, -1 * shift)
variance = sum(broadcast(abs, ((shiftedCounts / length(cipherText) - ENGLISH) / ENGLISH)))
variances[shift + 1] = variance;
end
println("The variance for each shift is calculated to be: \n", variances)
minshift = argmin(variances)
println("Inverse Caesar shift by ", minshift, " yielded minimal variance of ", variances[minshift], " respect to frequency of letters in ENGLISH...")
shiftedTextList = []
for letter in cipherText
code = Int(letter) - minshift
if code < Int('A')
code += 26
end
append!(shiftedTextList, Char(code))
end
shiftedText = join(shiftedTextList)
println("Deciphering minimal variance shifted text: ", shiftedText, " with columnar transposition...")
#Installing combinatorics library:
#import Pkg; Pkg.add("Combinatorics")
#Installing progress meter:
#import Pkg; Pkg.add("ProgressMeter")
using Combinatorics
using ProgressMeter
filename = "./google-10000-english.txt"
println("Loading common words DICTIONARY from: ", filename)
DICTIONARY = readlines(filename)
for width in 2:10
println("Applying columnar transposition with width: ", width)
matrix = []
height = Int(ceil(length(shiftedText) / width))
total = width * height
for index in 1:total
if index <= length(shiftedText)
append!(matrix, shiftedText[index])
else
append!(matrix, "?")
end
end
matrix = reshape(matrix, (height, width))
orders = collect(permutations(collect(1:width)))
completed = 0
n = length(orders)
p = Progress(n, 1, "Computing all permutations:", 50, :black)
bestPlainText = "?"
bestPlainTextCommonPercentage = 0
for permutation in orders
plainTextMatrix = []
for row in 1:height
for columnIndex in 1:width
char = matrix[row, permutation[columnIndex]]
if char != '?'
append!(plainTextMatrix, char)
end
end
end
plainText = join(plainTextMatrix)
wordCount = 0
wordLengthSum = 0
words = []
for word in DICTIONARY
if length(uppercase(word)) > 3 && occursin(uppercase(word), plainText)
wordCount += 1;
wordLengthSum += length(word)
push!(words, uppercase(word))
end
end
percentageCommon = wordLengthSum / length(plainText) * 100
if percentageCommon > 50
println("\rColumnar transposition with the order of: ", permutation, " yielded a string containing ", wordCount, " common word(s) which makes it ", percentageCommon, "% common words, below is the string:\n", plainText, "\ncontaining the words:\n", words)
if percentageCommon > bestPlainTextCommonPercentage
bestPlainText = plainText
bestPlainTextCommonPercentage = percentageCommon
end
println("Currently, the best plain text is:\n", bestPlainText, " which is ", bestPlainTextCommonPercentage, "% common words...")
end
next!(p)
end
end

Sobre o autor
Shen Huang costumava ser um garoto de roteiro quebrando o computador dos pais quando tinha 12 anos, causando um monte de dores de cabeça aos especialistas em segurança da rede na escola. Atualmente, ele está interessado em muitas áreas e começou a voltar aos seus interesses em cibersegurança. Shen está particularmente olhando para a segurança cibernética com biometria humana e inteligência artificial, pois ele acredita que será uma grande parte do futuro da cibersegurança.
Perfil do Shen’s GitHub:https://shenhuang.github.io/
O conteúdo foi originalmente publicado em:https://hackernoon.com/julia-a-language-for-the-future-of-cybersecurity-76f13b869924