Fuzzy String Matching – Um Guia Prático
Este artigo foi publicado como parte doData Science Blogathon
Fuzzy string matching é a técnica de encontrar strings que correspondem a uma determinada string parcialmente e não exatamente. Quando um usuário escreve uma palavra incorretamente ou insere uma palavra parcialmente, a correspondência de cadeias de caracteres difusa ajuda a encontrar a palavra certa – como vemos nos mecanismos de pesquisa.
O algoritmo por trás da correspondência de cadeias de caracteres difusa não olha simplesmente para a equivalência de duas cadeias de caracteres, mas quantifica o quão próximas duas cadeias de caracteres estão uma da outra. Isso geralmente é feito usando uma métrica de distância conhecida como “distância de edição”. Isso determina a proximidade de duas cadeias de caracteres, identificando as alterações mínimas necessárias a serem feitas para converter uma cadeia de caracteres em outra. Existem diferentes tipos de distâncias de edição que podem ser usadas como distância de Levenshtein, distância de Hamming, distância de Jaro, etc.
Vamos ilustrar como a distância de Levenshtein é calculada.
Exemplo 1:
String 1 = ‘Put’
String 2 = ‘Pat’
A distância de Levenshtein seria 1, pois podemos converter a string 1 em string 2 substituindo ‘u’ por ‘a’.
Exemplo 2:
String 1 = ‘Sol’
String 2 = ‘Saturno’
A distância de Levenshtein seria 3, pois podemos converter a string 1 em string 2 por 3 inserções – ‘a’, ‘t’ e ‘r’.
Correspondência de sequência de caracteres difusa em Python:
Comparando cadeias de caracteres em Python
Para comparar duas cadeias de caracteres em python, podemos executar o seguinte código:

O código acima dará uma saída como ‘False’, pois as duas cadeias de caracteres não são as mesmas.
Distância de Levenshtein em Python
Distância de Levenshtein em Python usando o pacote python ‘Levenshtein’.
import Levenshtein as lev
Str1 = "Back"
Str2 = "Book"
lev.distance(Str1.lower(),Str2.lower())
O código acima dará uma saída de 2 podemos converter string 1 para string 2 por 2 substituições.
FuzzyWuzzy em Python
FuzzyWuzzy é um pacote python que pode ser usado para correspondência de strings. Podemos executar o seguinte comando para instalar o pacote –
pip install fuzzywuzzy
Assim como o pacote Levenshtein, FuzzyWuzzy tem uma função de razão que calcula a razão de similaridade de distância de Levenshtein padrão entre duas sequências.
from fuzzywuzzy import fuzz
Str1 = "Back"
Str2 = "Book"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
print(Ratio)
A saída do código a seguir dá 50 à medida que a razão de Levehshtein é calculada dividindo a distância de Levenshtein pelo máximo do comprimento da string1 e string 2.
Vamos calcular a proporção para outro conjunto de strings.
from fuzzywuzzy import fuzz
Str1 = "My name is Ali"
Str2 = "Ali is my name"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
print(Ratio)
A saída do código dá 50 indicando que, embora as palavras sejam as mesmas, a ordem das palavras é importante ao calcular a proporção.
Proporção Parcial usando FuzzyWuzzy
A razão parcial nos ajuda a executar a correspondência de substrings. Isso pega a cadeia de caracteres mais curta e a compara com todas as substrings do mesmo comprimento.
Str1 = "My name is Ali"
Str2 = "My name is Ali Abdaal"
print(fuzz.partial_ratio(Str1.lower(),Str2.lower()))
A saída do código dá 100 como partial_ratio() apenas verifica se uma string é uma substring da outra.
Essa proporção pode ser muito útil se, por exemplo, estivermos tentando combinar o nome de uma pessoa entre dois conjuntos de dados. No primeiro conjunto de dados, a cadeia de caracteres tem o nome e o sobrenome da pessoa e, no segundo conjunto de dados, a cadeia de caracteres tem o primeiro, o meio e o sobrenome da pessoa. A proporção seria 100 porque a primeira cadeia de caracteres é uma subcadeia de caracteres na segunda cadeia de caracteres.
Token Sort Ratio usando FuzzyWuzzy
Na proporção de classificação de token, as cadeias de caracteres são tokenizadas e pré-processadas convertendo em minúsculas e se livrando da pontuação. As cadeias de caracteres são então classificadas em ordem alfabética e unidas. Depois disso, a razão de similaridade da distância de Levenshtein é calculada entre as strings.
Str1 = "My name is Ali"
Str2 = "Ali is my name"
print(fuzz.token_sort_ratio(Str1,Str2))
A saída do código fornece 100, pois a proporção de classificação do token é encontrada depois de classificar as cadeias de caracteres em ordem alfabética e, portanto, a ordem original das palavras não importa.
Token Set Ratio usando FuzzyWuzzy
A taxa de conjunto de tokens executa uma operação de conjunto que retira os tokens comuns em vez de apenas tokenizar as cadeias de caracteres, classificar e, em seguida, colar os tokens novamente. Palavras extras ou repetidas não importam.
Str1 = "My name is Ali"
Str2 = "Ali is my name name"
print(fuzz.token_sort_ratio(Str1,Str2))
print(fuzz.token_set_ratio(Str1,Str2))
A saída da taxa de classificação de token chega a ser 85, enquanto a da taxa de conjunto de token chega a ser 100, pois a taxa de conjunto de token não leva em conta as palavras repetidas.
Vamos ilustrar outro exemplo para a proporção do conjunto de tokens para uma explicação mais profunda.
Str_A = 'Read the sentence - My name is Ali'
Str_B = 'My name is Ali'
ratio = fuzz.token_set_ratio(Str_A, Str_B)
print(ratio)
A saída do código acima nos dá 100. Isso ocorre porque, sob o capô, a proporção do conjunto de tokens tem uma abordagem mais flexível. Depois de retirar as cadeias de caracteres comuns (‘Meu nome é Ali’), ele descobre a proporção de difusão para os seguintes pares e, em seguida, retorna o valor máximo entre os três:
- cadeia de caracteres comum e a cadeia de caracteres comum com o restante da cadeia de caracteres um
- cadeia de caracteres comum e a cadeia de caracteres comum com o restante da cadeia de caracteres dois
- cadeia de caracteres comum com o restante de uma e cadeia de caracteres comum com o restante de duas
Módulo de processo usando FuzzyWuzzy
Se tivermos uma lista de strings e quisermos encontrar a string correspondente mais próxima da lista com uma determinada string, podemos aproveitar o módulo ‘process’.
from fuzzywuzzy import process
query = 'My name is Ali'
choices = ['My name Ali', 'My name is Ali', 'My Ali']
# Get a list of matches ordered by score, default limit to 5
process.extract(query, choices)
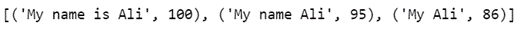
Se quisermos extrair a correspondência superior, podemos executar o seguinte código:
process.extractOne(query, choices)
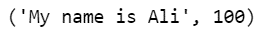
Sobre o Autor
Nibedita completou seu mestrado em Engenharia Química pelo IIT Kharagpur em 2014 e atualmente trabalha como consultora sênior na AbsolutData Analytics. Em sua capacidade atual, ela trabalha na construção de soluções baseadas em IA / ML para clientes de uma variedade de indústrias.
As mídias mostradas neste artigo não são de propriedade da Analytics Vidhya e são usadas a critério do Autor.