Implantando o Controle de Dependência como um Contêiner do Docker no Azure e criando um PipeLine com o Azure Devops
Implantando o Controle de Dependência como um Contêiner do Docker no Azure e criando um PipeLine com o Azure Devops

Neste artigo, mostrarei como implantar o OWASP Dependency Track em um Contêiner do Azure e usá-lo como um aplicativo.
Também mostrarei como configurar um pipeline no Azure Devops que criará um Arquivo BOM (Com base em seu arquivo csproj em seu repositório) e o enviará para o Aplicativo do Azure que criamos anteriormente para ser analisado e armazenado.
Para poder fazer isso, você só precisará de uma conta gratuita do Azure Devops e de uma conta gratuita do Portal do Azure.
No Portal do Azure, iremos:
• Criar e configurar nosso Banco de Dados do SQL Server;
• Criar e configurar o Docker Container e Registry;
• Criar e configurar o Aplicativo para executar nossa imagem de contêiner.
No Azure Devops, iremos:
• Criar e configurar nosso pipeline para enviar o arquivo de lista técnica necessário a ser analisado.
NOTA: O repositório que estou usando para criar meu pipeline tem um projeto de API Web do .NET Core e é esse projeto que analisarei com o Dependency Track.
Se vocês quiserem configurar o Dependency Track com o Azure AD OpenID Connect, você pode verificar este artigo que eu escrevi: https://lyny-leandro.medium.com/dependency-track-with-azure-ad-openid-connect-b2d13861c4f5
Então, antes de começarmos…
… vamos ver qual é a principal tecnologia que vamos contornar que é o Dependency Track!
Rastreador de dependência OWASP: “O Dependency-Track é uma plataforma inteligente de Análise de Componentes da Cadeia de Suprimentos que permite que as organizações identifiquem e reduzam o risco do uso de componentes de terceiros e de código aberto.”
src: https://owasp.org/www-project-dependency-track/
Você pode obter mais informações sobre isso em seu site, que tem muitas informações úteis e documentação, mas basicamente o Dependency Track é um software que analisará suas dependências e bibliotecas em seu aplicativo e procurará qualquer vulnerabilidade conhecida sobre elas. Ele também informará se as bibliotecas e dependências estão desatualizadas ou preteridas.
Seu site com sua documentação: https://docs.dependencytrack.org/
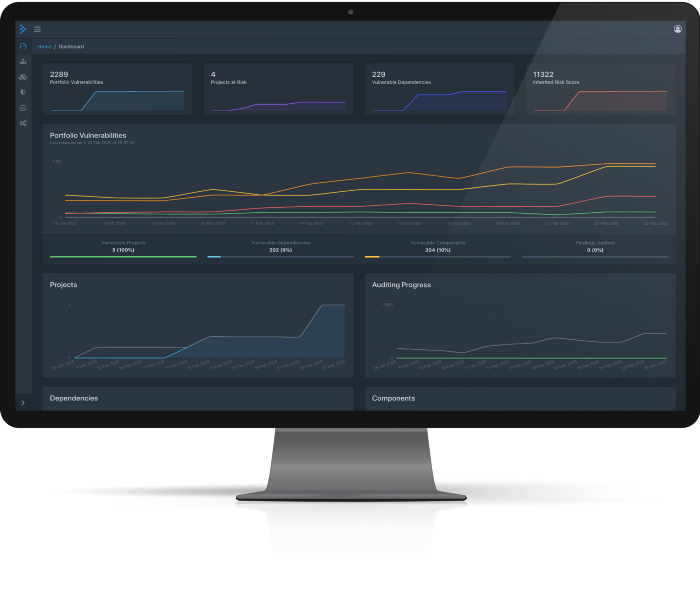
Painel de Controle de Dependência
Requisitos do contêiner
Conforme indicado em sua documentação para executar o Dependency Track em um contêiner, você precisa dos seguintes requisitos de contêiner:
**Mínimo:
**4.5GB RAM
2 núcleos de CPU
Recomendado:
16GB RAM
4 núcleos de CPU
Você pode conferir mais informações sobre este assunto em:
https://docs.dependencytrack.org/getting-started/deploy-docker/
Com todas as informações relevantes fora do caminho…
… Vamos começar!
Em primeiro lugar, vamos dar uma olhada no arquivo yml que usaremos para configurar nosso contêiner no Azure.
Como você pode ver, em nosso arquivo, temos algumas coisas muito importantes, como a Conexão de Banco de Dados, o Driver que precisaremos e a imagem que usaremos, que é a Trilha de Dependência, o volume que é muito importante e o caminho para o nosso motorista.
Você pode baixar o driver do SQL Server aqui: https://www.microsoft.com/en-us/download/details.aspx?id=100855
Para este artigo médio específico, usaremos o driver Java 8 SQL Server.
Vamos começar com nosso volume:
Como estamos implantando-o no Azure, precisaremos usar a seguinte variável de ambiente ${WEBAPP_STORAGE_HOME} e, em seguida, o caminho do site onde armazenamos nosso driver.
O segmento /data/ no volume é o caminho padrão em nosso contêiner que é criado, portanto, estamos basicamente vinculando nosso diretório de Site do Azure ao nosso Volume de contêiner para que ele possa encontrar o driver. (Isso será mais fácil de entender quando criarmos tudo em azure).
Driver Path:
Esta linha em nosso código ALPINE_DATABASE_DRIVER_PATH=~/driver.jar será traduzida para /data/driver.jar na qual, como expliquei acima, será vinculada ao nosso caminho wwwroot do aplicativo.
E por fim…
A Conexão de Banco de Dados: É realmente autoexplicativo, é a nossa Conexão
de Banco de Dados para armazenar todas as informações necessárias para o nosso aplicativo de Rastreamento de Dependência ser executado.
Vamos pular para o Azure e vamos criar e configurar nosso banco de dados.
Vá para a guia “Criar recurso” e selecione Banco de dados. Na seção Bancos de dados, selecione “Banco de dados SQL”.
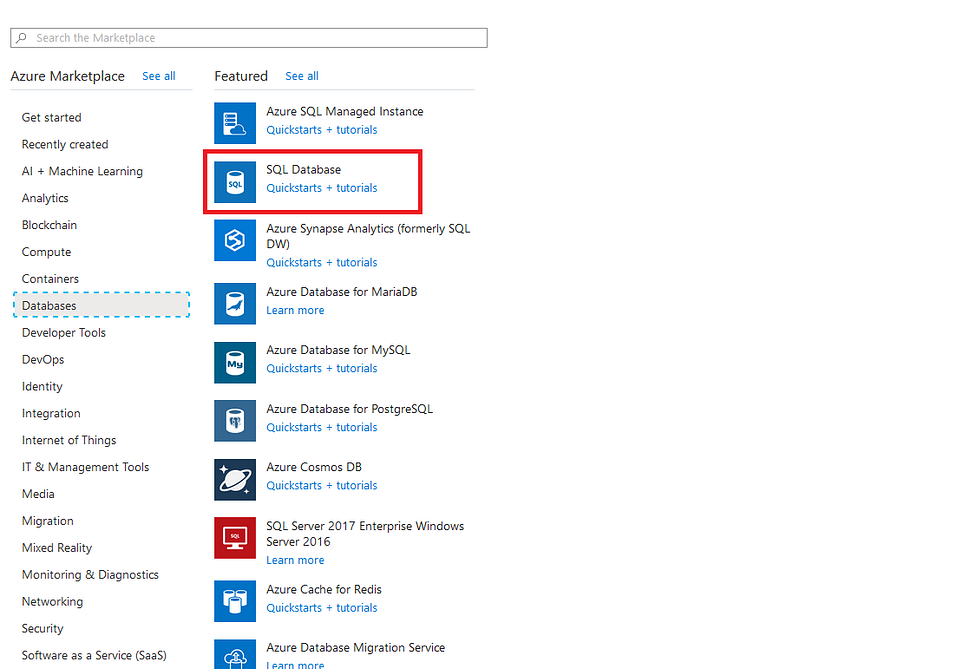
Você será recebido com um painel para criar o nome do banco de dados e definir todas as configurações do banco de dados. Nesta imagem, estou usando os nomes que estou usando no arquivo YML, é claro que você pode alterá-los para atender ao seu gosto!
Você pode deixar o armazenamento padrão, como para este artigo demonstração é mais do que suficiente!
Você pode pular para a guia “Revisar + Criar”, pois isso é tudo o que você precisará para definir seu banco de dados.
Depois de pressionar o botão continuar para criar seu Banco de Dados, você precisará aguardar um pouco para que isso seja feito, quando estiver, vá para o Recurso de Banco de Dados que você criou. (Será no seu Grupo de Recursos que você o definiu como sendo ou no seu painel padrão).
Você será recebido com o seguinte painel de visão geral:
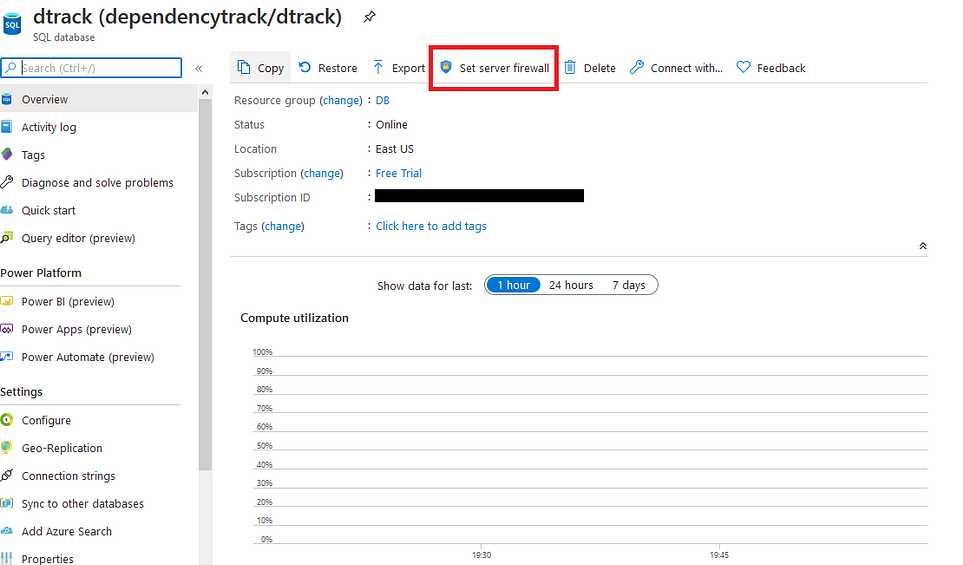
Você precisará clicar na configuração “Definir firewall do servidor”.
Por enquanto, você ou qualquer outro endereço IP tem acesso ao seu banco de dados e, para este artigo, alteraremos isso e faremos com que todos os IPs tenham acesso a ele.
Normalmente, quando você tenta se conectar a um Banco de Dados do Azure, você se depara com uma interface para adicionar seu IP a uma Lista Branca, já que queremos que nosso Aplicativo tenha acesso a ele e não queremos nenhum problema com problemas de acesso ao Banco de Dados, configuraremos isso.
Observe que é sempre viável que você só coloque o acesso a endereços IP restritos por motivos de segurança.
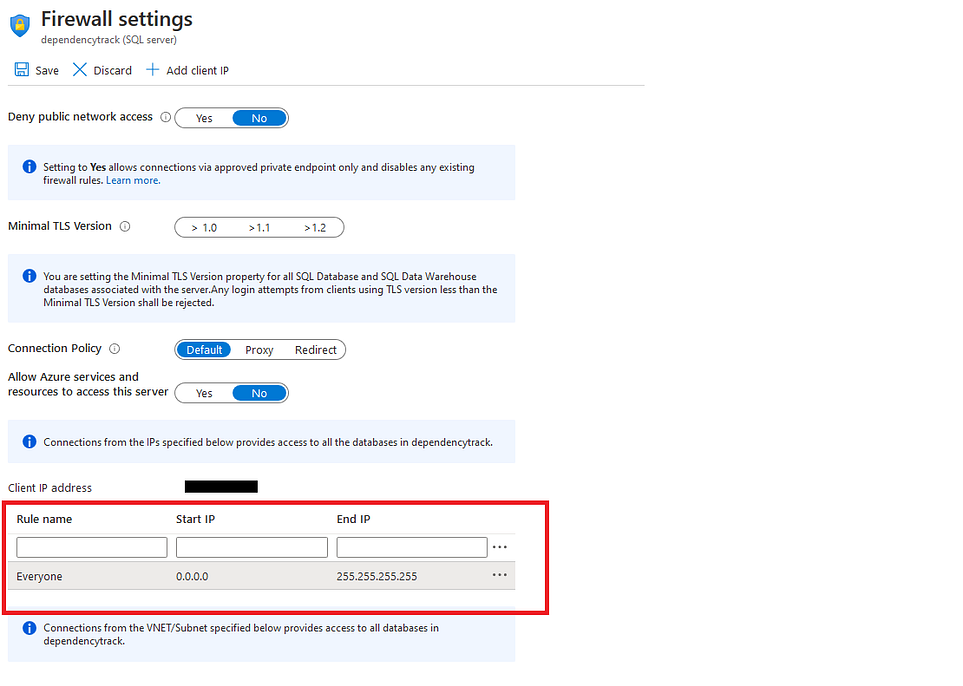
Depois de configurar o “Start IP” para ser 0.0.0.0 e o “End IP” para 255.255.255.255, clique na opção Salvar e isso é tudo.
Você tem um banco de dados criado e configurado para executar o controle de dependência.
Você pode testar sua conexão com o banco de dados que você criou em sua máquina local.
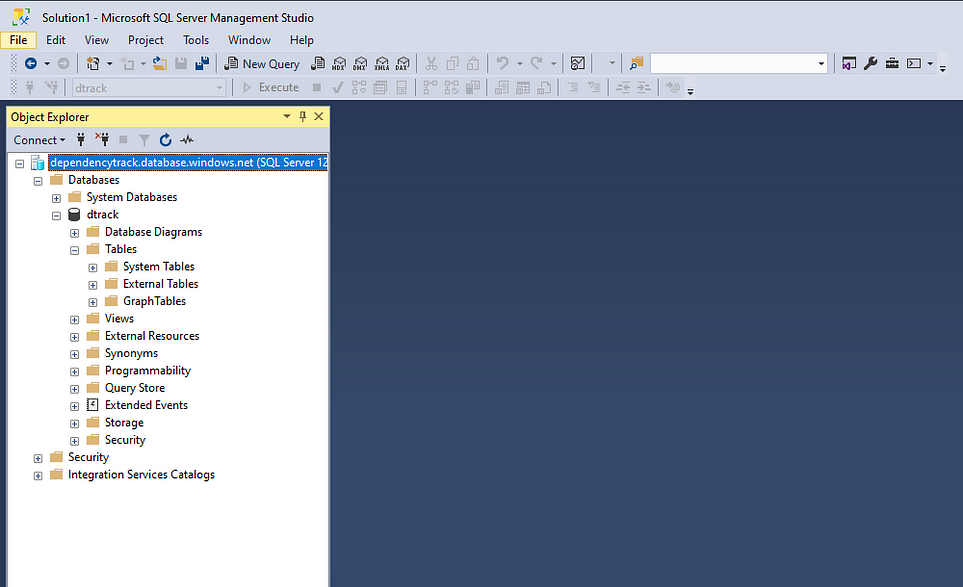
Como você pode ver, eu posso me conectar ao banco de dados que eu criei, o que é bom!
Agora que temos a nossa Base de Dados…
… Vamos pular para a nossa Criação e Configuração de Contêineres!
Vamos criar nosso Registro de Contêiner
Vá para “Criar um Recurso” e procure em Contêineres > Registro de Contêineres.
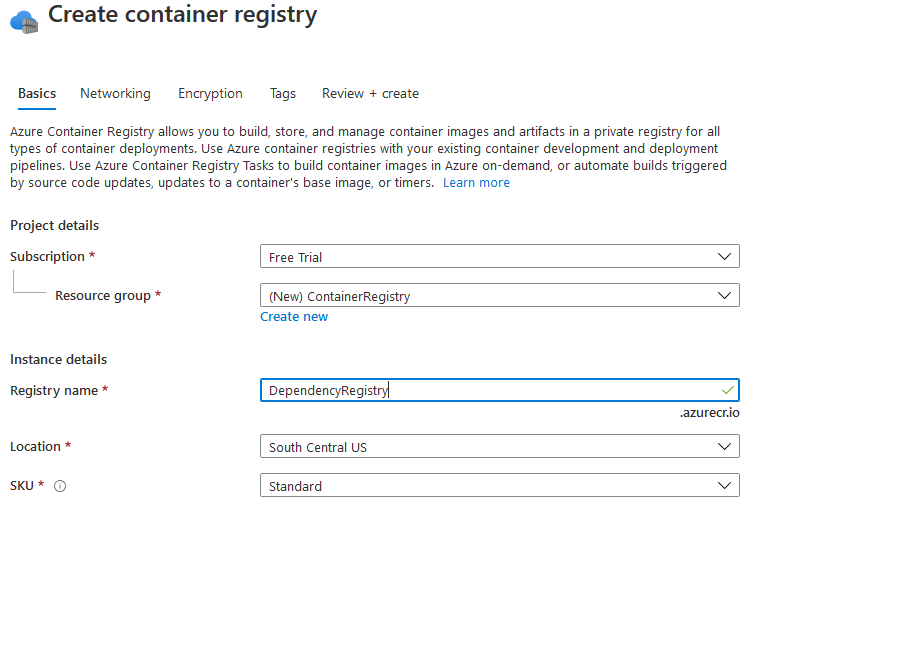
Assim como outros, você será solicitado a preencher algumas informações. É realmente simples e você só precisa nomear seu Registro e criar ou selecionar um Grupo de Recursos para ele.
Quando você terminar de fazê-lo, você precisará navegar até o local do recurso para que você possa ativar a opção de chaves de acesso, na qual lhe dará um usuário e 2 senhas.

Depois de clicar na guia “Chaves de acesso”, basta “Ativar” a opção “Usuário Administrador” e está tudo pronto e pronto. Temos nosso Registro de Contêiner Criado e Configurado.

Agora, vamos criar e configurar nosso aplicativo web para o nosso contêiner …
… Na verdade, esta é a parte mais complicada de todo este artigo. Bem, não é difícil por si só, mas temos algumas configurações que temos que fazer e entender por que estamos fazendo-as.
Começamos indo para “Criar um recurso” e, em seguida, procuramos em Contêineres > aplicativo Web para contêineres.
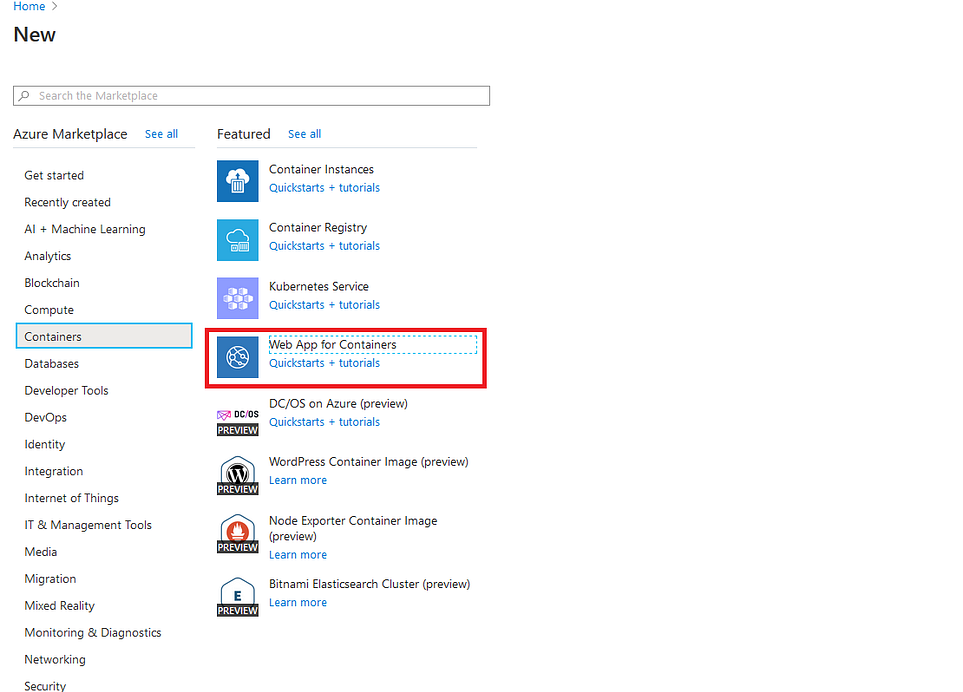
Você precisará preencher algumas informações relevantes, como o nome, criá-lo ou adicioná-lo a um grupo de recursos já existente (Este procedimento parece familiar?).

Mas há uma pequena mudança que você precisa fazer na guia “Básico”, que é o “Sku e Tamanho”. Precisamos alterar nosso “Sku e Tamanho” para atender aos nossos Requisitos de Contêiner para Rastreamento de Dependência.
Eu aumentei para um pouco acima dos requisitos mínimos que mencionei em uma das seções deste artigo, mas você pode escolher o que quiser, apenas certifique-se de que atenda aos requisitos mínimos ou acima dos requisitos mínimos para que seu aplicativo de contêiner funcione sem problemas.
Vamos pular para a “guia Docker”.
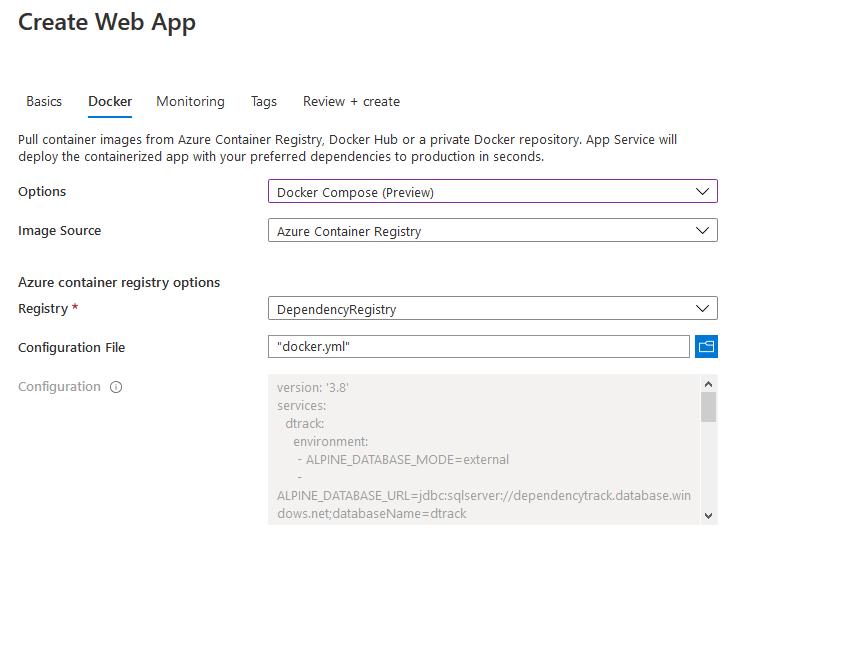
Aqui, escolheremos “Docker Compose” como nosso conjunto de “Opções” e escolheremos nossa “Origem da Imagem” para ser “Registro de Contêiner do Azure”. Em seguida, tudo o que você precisa fazer é selecionar o Registro que você criou (No meu caso, foi “DependencyRegistry”) e escolher o Arquivo de Configuração, que é o arquivo YML sobre o qual discutimos anteriormente neste artigo.
Você pode ir para a guia “Revisar + Criar” e criar seu Contêiner de Aplicativo Web.
Depois de criado, vá para o local do aplicativo Web e pare-o. Precisaremos fazer algumas configurações antes de avançarmos.
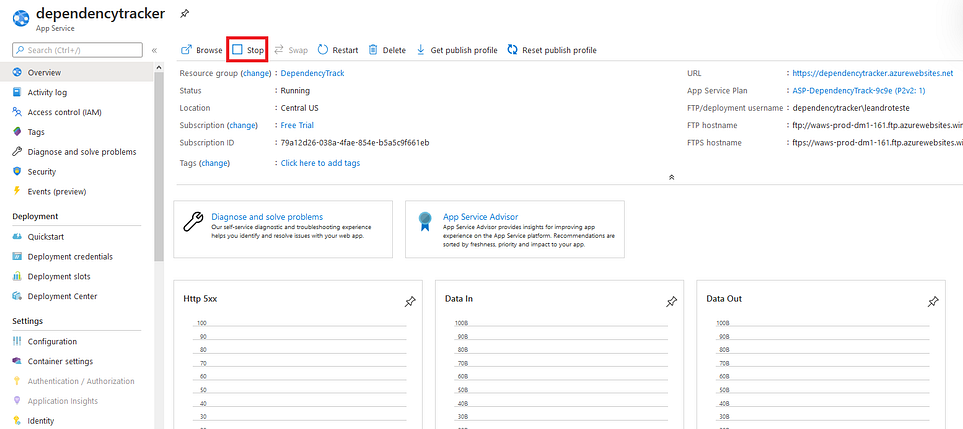
Agora que nosso aplicativo Web está parado, vamos pular para a guia “Credenciais de implantação” e configurar nossa senha para nossa conexão FTP na qual usaremos para criar nossas pastas e carregar nosso driver.
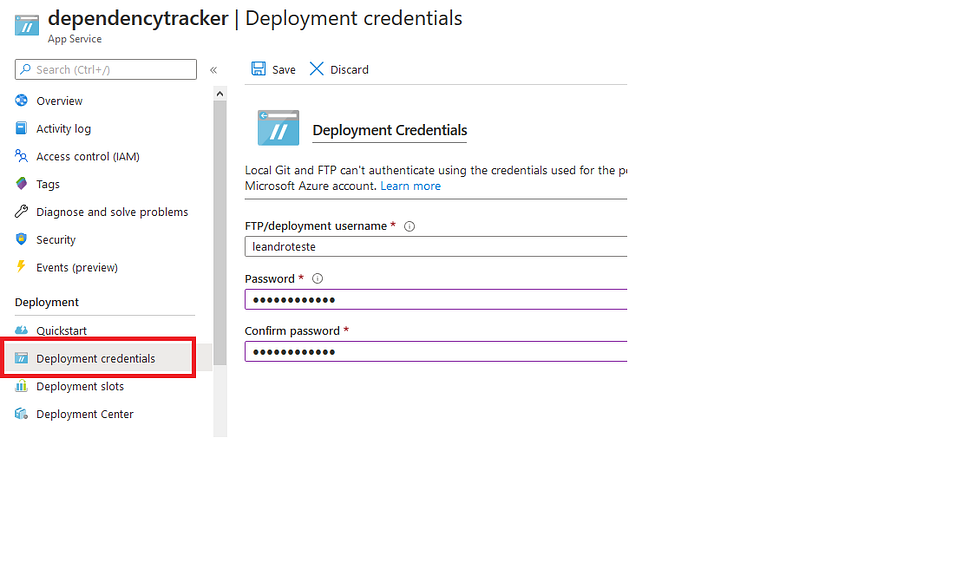
Salve-o e volte para a guia Visão Geral. Você encontrará algo chamado “FTP Hostname”. Copie esse link e pule para o seu cliente FTP para que possamos usá-lo para acessar nosso sistema de arquivos de aplicativos. Eu estarei usando FileZilla neste exemplo e ele vai olhar mais ou menos assim.

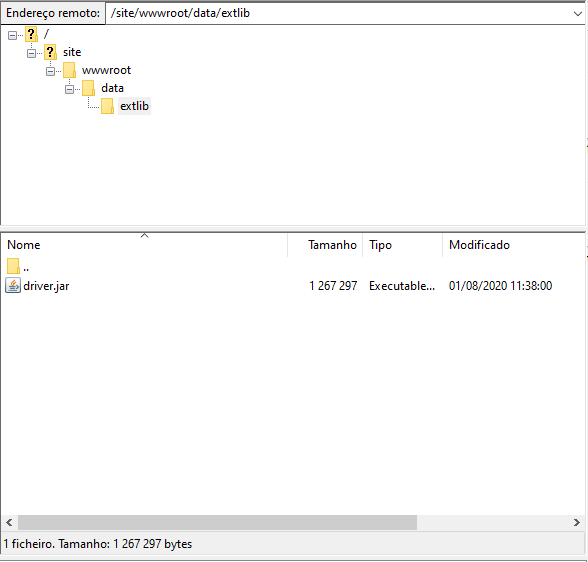
Lembra-se do volume sobre o qual falamos anteriormente no arquivo YML? Tínhamos esse caminho “${WEBAPP_STORAGE_HOME}/site/wwwroot/data/extlib/”. Nós só precisaremos criar “/data/extlib/” dentro de /wwwroot e fazer o upload do nosso driver para /**extlib/
**Na imagem abaixo você pode ver isso feito.
NOTA: Você precisa definir o caminho do arquivo da maneira que você defini-lo no arquivo YML, no meu caso, eu defini-lo desta forma, mas você é livre para fazer o que quiser!
Com isso fora do caminho, ainda precisamos fazer algumas outras configurações para que isso funcione, pois, por enquanto, não é suficiente.
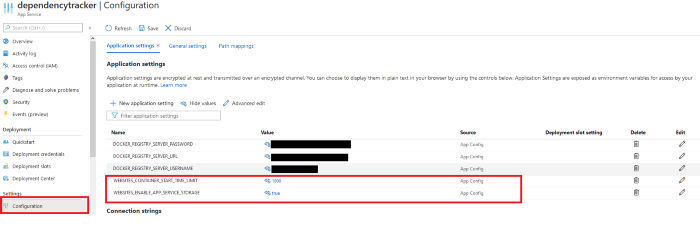
Você precisará mudar para a guia “Configuração” e alterar 1 variável e adicionar uma nova.
Nome da configuração: WEBSITES_ENABLE_APP_SERVICE_STORAGE
Para que nosso contêiner saiba que estamos usando um Armazenamento de Volume e para vinculá-los entre nosso Serviço de Aplicativo e o Contêiner, você precisará alterar seu valor para “true”, já que o valor padrão é definido como “false”.
Nome da configuração: WEBSITES_CONTAINER_START_TIME_LIMIT
Precisaremos criar essa configuração para que nosso aplicativo seja executado e não atinja o tempo limite quando a imagem do contêiner estiver sendo criada. Como o Dependency Track tem uma construção de imagem lenta (leva cerca de 20/25 minutos para criar), precisamos criar essa configuração e definir seu valor como “1800”, o que se traduz em nosso contêiner ter 30 minutos para iniciar!
Salve suas configurações e você pode iniciar o aplicativo!
Sua configuração será semelhante à imagem acima.
Aguarde cerca de 20 minutos até que tudo esteja pronto e pronto.
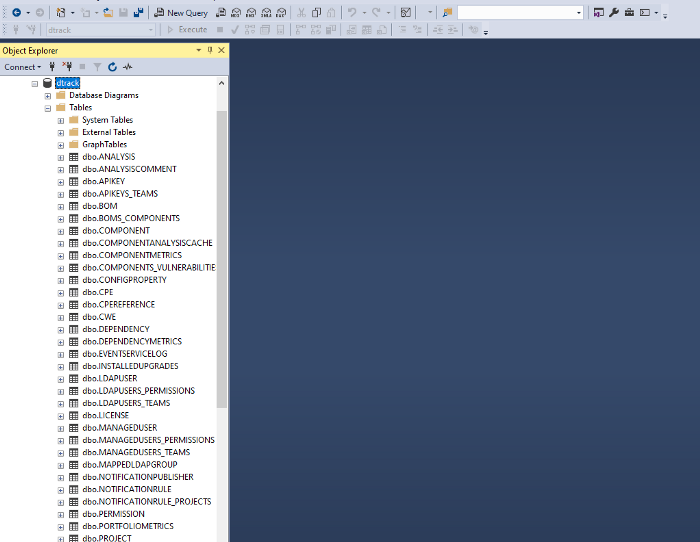
Se formos ao nosso Banco de Dados, veremos algumas tabelas que foram criadas para que nosso aplicativo pudesse ser executado.
E se copiarmos e colarmos o URL do nosso Aplicativo no navegador e pressionarmos enter, teremos essa página aparecendo, o que é ótimo, já que esta é a nossa página de Login de Rastreamento de Dependência!
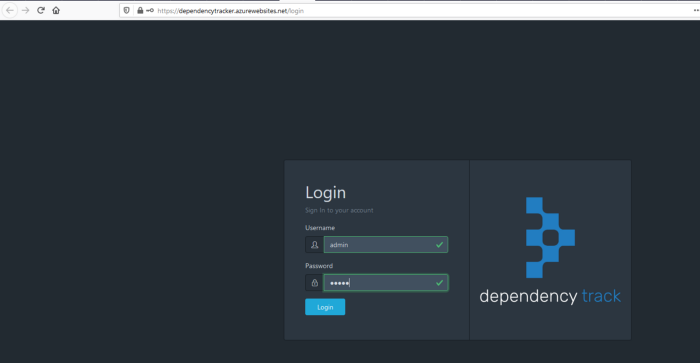
O login padrão é: Nome de usuário: admin Senha:
admin
Depois de fazer login, ele irá promt uma janela para você alterar a senha de administrador. Depois de concluir isso e fazer login com as novas credenciais, você será recebido com este Painel de Rastreamento de Dependência.
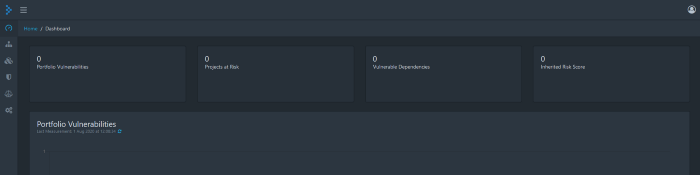
Antes de irmos para o Azure Devops para configurar nosso Pipeline para trabalhar com nosso Aplicativo, precisaremos criar um projeto, obter a ID do projeto e a Chave de API.
Então, vamos para a nossa guia “Projeto” e vamos Criar um Projeto.

Um pop-up modal aparecerá para você inserir algumas informações sobre o seu projeto. Preencha o formulário como desejar e, quando estiver satisfeito com o que tem, pressione o botão “Criar”.
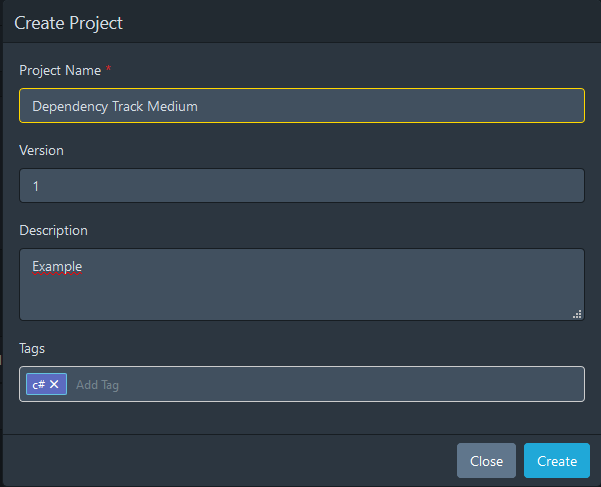
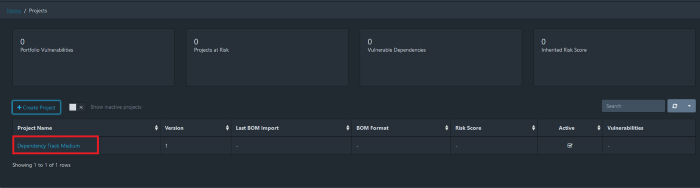
Um novo projeto aparecerá na Grade do Painel de Projetos, clique nele e você navegará até o próprio projeto. Está vazio por enquanto e é assim que vai ser até construirmos o nosso PipeLine para carregar o nosso arquivo BOM.
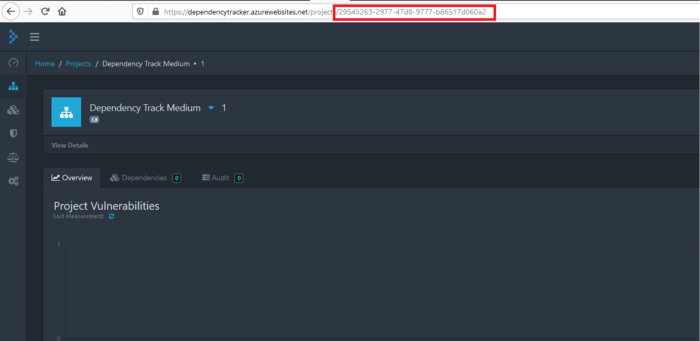
Uma vez que você está dentro, olhe para o seu URL e você terá um hash como string. Esse é o ID do projeto, copie-o e cole-o em um bloco de notas, você precisará dele mais tarde.
Agora, para a etapa final, precisaremos obter a chave da API. Para fazer isso, precisaremos navegar até a guia “Administração” dentro da guia vá para “Gerenciamento de acesso” lá selecione “Equipes” e selecione a conta que tem a API KEY na grade com o valor “1”. Depois de clicar nele, você será apresentado à seguinte tela.
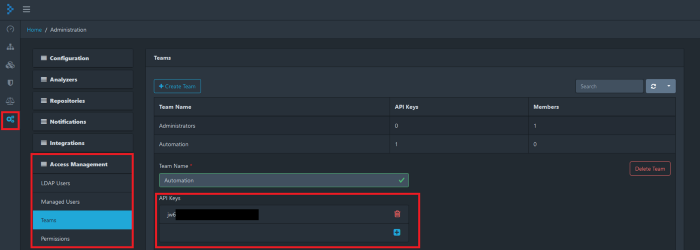
Mais uma vez, copie e cole a chave da API em um bloco de notas, pois precisaremos dela mais tarde.
Então, criamos nosso Projeto, temos a ID do Projeto e a Chave de API, estamos prontos para ir para nossa Conta do Azure Devops e criar nosso PipeLine, então vamos lá!
Agora que temos tudo pronto e feito, vamos construir o nosso Pipeline.
Você pode fazer isso com uma extensão do Dependency Track no mercado, que é gratuito, mas você não o exportará para o seu aplicativo Dependency Track automaticamente e leva até 3/4 minutos apenas para analisar o arquivo csproj.
Qual é o problema sobre os mais de 3/4 minutos de tempo?
Bem, no Azure Devops você paga pelo tempo que seu Pipeline leva para terminar, imagine que você definiu um grupo de Pipelines para trabalhar em seu plano de CI/CD e você tem SEMPRE que analisar suas dependências e bibliotecas, isso se somará e no final do mês você sentirá isso.
Então, quais são as vantagens de fazê-lo dessa maneira?
Para começar, você tem seu próprio Painel personalizado de Rastreamento de Dependência, eu o tenho em um contêiner no Azure, para este exemplo, mas você pode tê-lo em seu próprio servidor em execução em um contêiner ou não.O pipeline que vamos criar leva menos de 1 minuto, na melhor das hipóteses, para fazer todo o trabalho e além de exportar o Arquivo de BOM automaticamente para o seu projeto.
É claro que tudo depende do tamanho do seu projeto e de quantas dependências e bibliotecas você tem, mas, em geral, isso é muito eficaz.
Então, vamos começar e analisar o arquivo YML que vamos usar!
Neste YML temos 3 tarefas DotNet em que o primeiro é baixar o SDK do .NET na imagem
do ubuntu O segundo é baixar o CycloneDX, é o pacote que analisará e exportará nosso arquivo csproj para um arquivo BOM.
O terceiro é executar o comando CycloneDX para gerar nosso arquivo BOM.
A última é pegar nosso arquivo de BOM e enviá-lo para o Dependency Track.
Observe que você precisará alterar seu caminho para o seu repositório, no meu caso, é /Commander/Commander.csproj. Você também precisará adicionar seu ProjectId, API Key e URL de Rastreamento de Dependência na última seção do Arquivo YML.
Além de tudo isso, você precisa baixar do mercado uma biblioteca de Dependency Track para executar a última tarefa.
https://marketplace.visualstudio.com/items?itemName=GSoft.dependency-track-vsts
Com tudo isso fora do caminho…
… Vamos começar!
Faça logon no Azure Devops, se você ainda não tiver um projeto, crie um novo e vincule um repositório que tenha um projeto que você gostaria de analisar.
No meu exemplo, usarei uma API Web do .NET Core
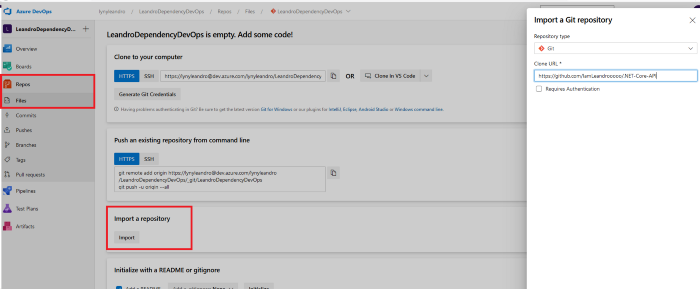
Agora, precisaremos criar um Pipeline. Vá para a guia Pipeline e clique onde está escrito “Create Pipeline”. Você será então apresentado a uma interface com muitas opções, escolha a que diz “Use o editor clássico”

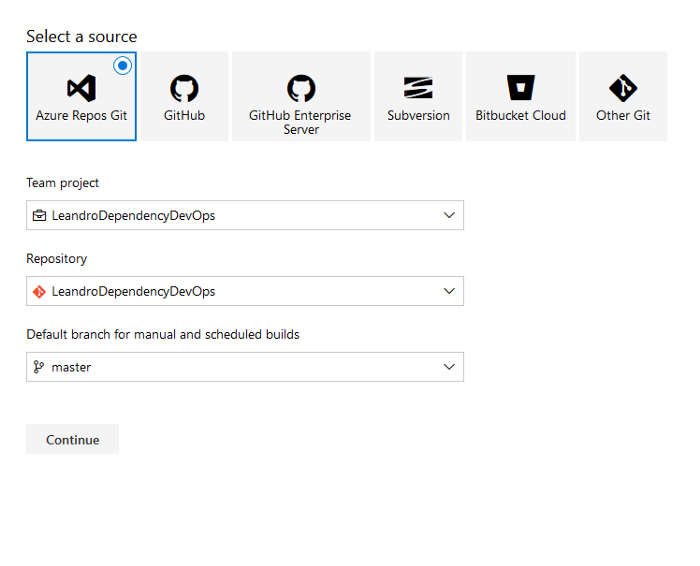
Selecione seu Repositório e clique em continuar. No meu caso, usarei o Azure Repos Git.
Depois de clicar em continuar, você irá para uma interface que mostrará todos os modelos que você pode usar para criar seu pipeline. Vamos escolher o YAML.
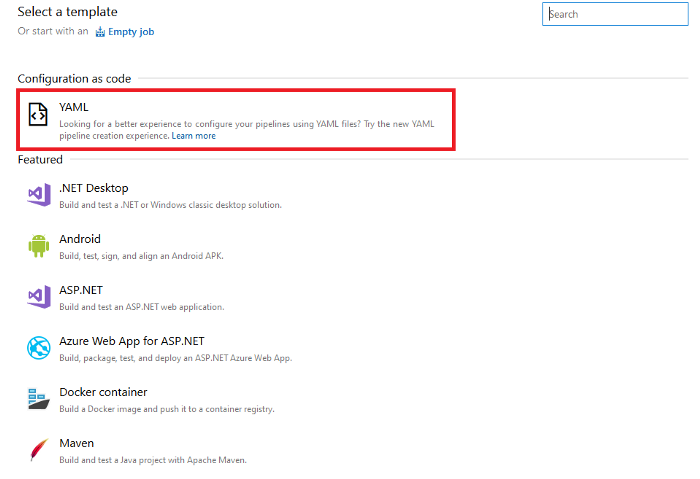
Importe o arquivo YML para o repositório e selecione o caminho no qual você o colocou.
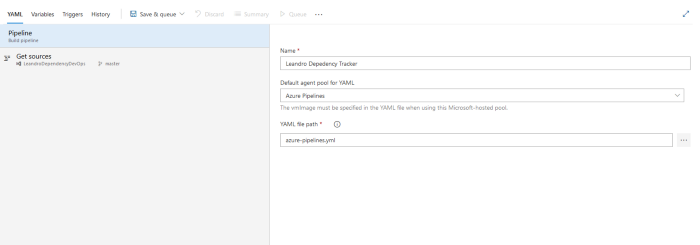
Quando tudo estiver pronto, salve seu pipeline. Agora vá para a guia Pipelines e você deve ter o Pipeline que você salvou criado! Clique nele e execute-o e aguarde que um agente esteja disponível para executar seu pipeline.
Você deve ter a seguinte tela quando você vai para a interface Pipeline Job.
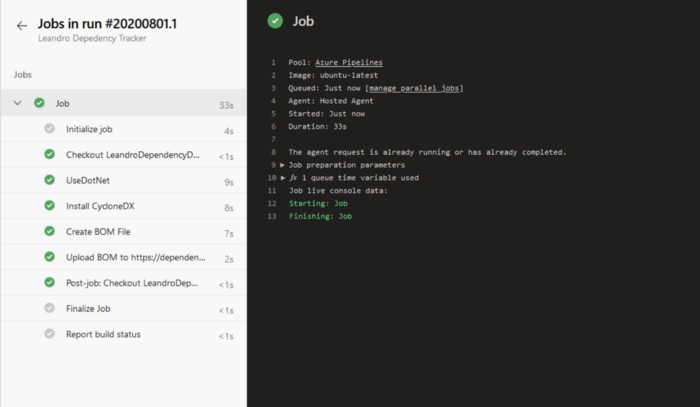
Como você pode ver, para este projeto, levou apenas 33 segundos para analisar e fazer todo o trabalho de enviá-lo para o meu aplicativo de rastreamento de dependência.
Se o trabalho falhou, você deve ter configurado algo errado, mais uma vez:
• Não se esqueça de alterar o arquivo YML para direcionar seu .csproj;
• Não se esqueça de alterar a API Key, a chave do Project e a URL do Aplicativo;
• Não se esqueça de baixar a biblioteca no mercado Azure Devops para a conta que está executando o Pipeline!
Biblioteca para download: https://marketplace.visualstudio.com/items?itemName=GSoft.dependency-track-vsts
Então, vamos verificar o nosso aplicativo de rastreamento de dependência!
Quando vou ao meu Painel de Projetos, posso ver que algo foi carregado no momento em que o pipeline terminou!
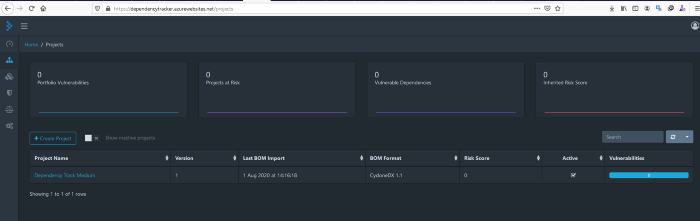
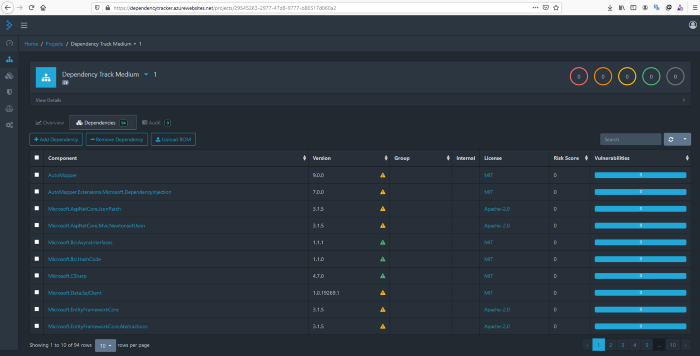
Quando entro no projeto posso ver que tenho dependências que foram analisadas, o que significa que FUNCIONOU!
Meu pipeline enviou com sucesso o arquivo de BOM que foi gerado para o meu aplicativo e ele foi analisado automaticamente e posso ver que não tenho vulnerabilidades em minhas dependências e bibliotecas!
Conclusão
Abordamos muitos tópicos neste artigo sobre o Portal do Azure, o Azure Devops, os Arquivos YML, os contêineres e o Controle de Dependência.
Espero que você tenha achado este artigo útil e que tenha achado o Dependency Track uma obrigação para adicionar à sua coleção de aplicativos para verificar suas vulnerabilidades de aplicativos. Lembre-se de que a segurança é muito importante e é sempre bom ter uma verificação dupla em coisas que às vezes tomamos como garantidas, como nossas dependências e bibliotecas sendo seguras!
Às vezes, desempenho e segurança não combinam bem e eu tentei o melhor que pude para otimizar um pipeline personalizado para ser um pouco mais rápido do que os outros que eu já vi.
Espero que vocês tenham aprendido algo novo com este artigo, com certeza fiz e foi um prazer escrever e tornar isso possível.