Teste Shift-Right - O Surgimento do TestOps
O conceito de deslocamento para a esquerda tem sido uma tendência popular nas práticas de teste contínuo há algum tempo. Agora estamos começando a ver as práticas de mudança de direita como uma tendência emergente nos testes.
Shift-right implica fazer mais testes nas fases imediatas de pré-lançamento e pós-lançamento (ou seja, testes em produção) do ciclo de vida do aplicativo. Isso inclui práticas como: validação de versão, teste destrutivo/caos, testes A/B e canários, testes baseados em CX (por exemplo, correlacionando o comportamento do usuário com os requisitos de teste), testes de multidão, monitoramento de produção, extração de insights de teste de dados de produção, etc.
O Shift-right não apenas introduz essas novas técnicas de teste, mas também exige que os testadores adquiram novas habilidades, façam uso agressivo dos dados de produção para conduzir estratégias de teste e colaborem com novas partes interessadas, como engenheiros de confiabilidade do local (SRE) e engenheiros de operações.
Na mudança para a direita dos testes, e no aumento da colaboração com as disciplinas de operações, vemos a evolução de uma nova disciplina em DevOps que chamamos de TestOps.
Neste blog, discutiremos as várias tendências e práticas de teste de mudança para a direita, o que as está impulsionando, as novas habilidades e colaboração necessárias para que os benefícios do TestOps possam ser realizados.

Tendências emergentes no teste de deslocamento para a direita
Em uma pesquisa recente de testes contínuos realizada em conjunto pela Capgemini e pela Broadcom, os testes em produção foram classificados como a prática número um (com 45% dos respondentes) atualmente implementada ou planejada (veja a Figura 1). Além disso, 39% dos entrevistados mencionaram o uso de análises de operações para determinar ou otimizar a cobertura de testes.
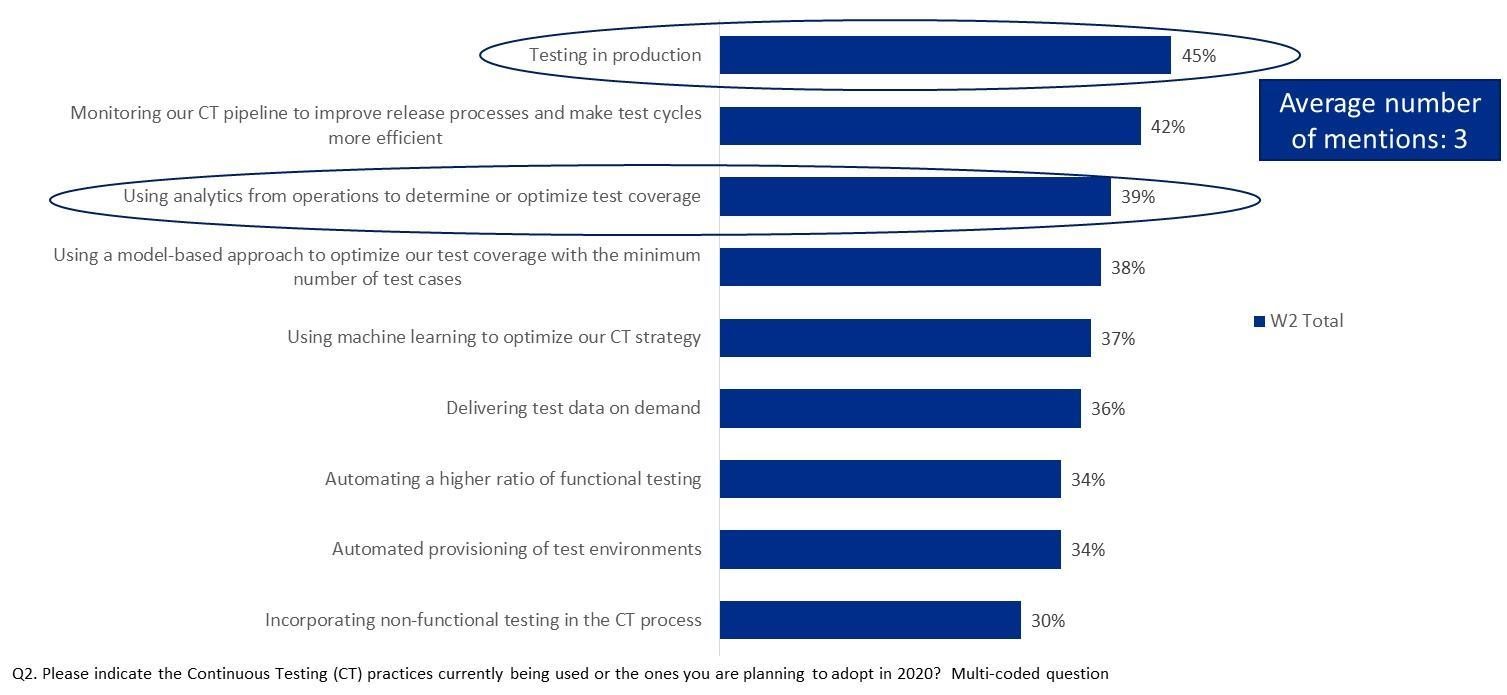
Gráfico 1.
Quando perguntados sobre como os clientes medem a eficácia dos processos de teste contínuos, os dados de produção e o feedback do usuário e a adoção de novas funcionalidades foram classificados em primeiro e segundo lugar, respectivamente (consulte a Figura 2).

Gráfico 2.
Finalmente, em resposta à forma como os clientes testam seus aplicativos digitais para garantir que eles atendam aos requisitos do mundo real, quase todas as respostas foram relacionadas aos dados de produção (consulte a Figura 3). O uso de dados de produção para projetar a estratégia de teste e os testes de caos surgiram como novos métodos em comparação com uma pesquisa semelhante feita há um ano.
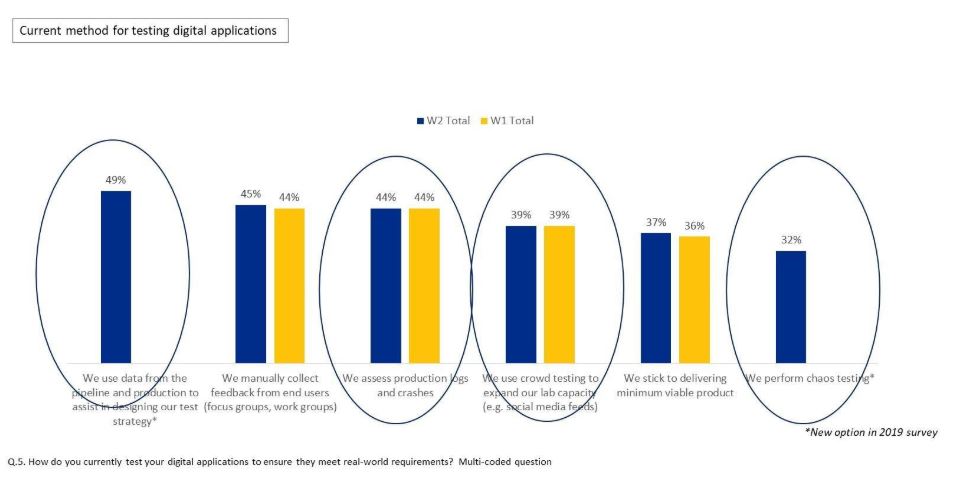
Gráfico 3.
Os dados da pesquisa indicam claramente que os clientes estão praticando ativamente (ou considerando a adoção de) técnicas de teste shift-right. Este relatório tem um capítulo (com minhas contribuições) dedicado à mudança para a direita que discute as técnicas e recomendações para sua adoção, bem como estudos de caso relevantes de clientes.
O que está impulsionando as tendências de teste de mudança para a direita?
O objetivo do teste shift-right é garantir o comportamento, o desempenho e a disponibilidade corretos durante a produção de um aplicativo.
Existem vários fatores para a adoção de tendências de teste de mudança para a direita.
A experiência do cliente (CX) é uma métrica de qualidade fundamental para aplicativos digitais
Ao contrário dos testes clássicos, isso leva em conta os usuários do mundo real e suas experiências. Um aplicativo com pontuações de qualidade tradicionais perfeitas (como o FURPS) ainda pode sofrer com CX ruim se não conseguir encantar o cliente. O CX é medido usando várias métricas, como Customer Effort Score (CES), Net Promoter Score (NPS), Customer Satisfaction Score (CSAT), etc. Embora seja possível deslocar para a esquerda algumas dessas medições em algum grau, a maioria das medições de CX é deduzida de sistemas em produção (ou próximos à produção). Exemplos de testes baseados em CX incluem o seguinte:
- Validação de requisitos com base em jornadas reais do usuário, comportamento e feedback.
- Derivando cenários de teste funcionais e de desempenho com base no acima.
- Testes A/B e testes canários, para experimentar o quão bem os clientes gostam (ou não gostam) das mudanças.
- Teste coletivo, para entender melhor a experiência do usuário no mundo real.
Em um mundo de entrega ágil, pode não ser possível testar tudo antes da liberação para produção
O tempo de lançamento no mercado (ou lead time para mudanças) é um dos principais imperativos de negócios para aplicativos digitais, e é por isso que o controle de qualidade/teste é considerado um grande gargalo na entrega contínua. Embora seja possível otimizar o esforço de teste e o tempo de ciclo usando práticas de deslocamento para a esquerda (como testes baseados em modelo, testes de impacto de alteração, automação de processos e execução de teste, etc.), essas abordagens ainda podem levar muito tempo (ou muito esforço) durante o tempo de ciclo de liberação reduzido. Em alguns casos, os padrões de uso exatos podem nem mesmo ser totalmente compreendidos antes do lançamento. A ideia é aprender padrões de uso da produção e usá-la para uma melhor estratégia de teste dentro do shift-left.
Sistemas complexos e cada vez mais distribuídos usando microsserviços (usando milhares de componentes) e técnicas nativas da nuvem que permitem lançamentos em um nível muito granular tornam cada vez mais difícil testar totalmente em ambientes de pré-produção. Isso é complementado pelo fato de que, como essas versões são tão granulares, elas podem ser retiradas facilmente (reversão) caso causem problemas.
Assim, as empresas testam para garantir qualidade “boa o suficiente” (para garantir a liberação em tempo hábil) e contam com remediação rápida (ou reversão) para resolver defeitos ou problemas que surjam.
Além disso, as medições de CX (como descrito acima) geralmente fornecem feedback do usuário real em tons de cinza, ao contrário da medição de aprovação/reprovação em preto e branco dos testes clássicos. O que significa que não é possível aperfeiçoar conjuntos de testes de pré-produção para garantir uma cobertura completa de CX.
Cem por cento de confiabilidade (ou qualidade) é muitas vezes uma meta irrealista
Relacionado ao acima, um dos principais princípios que aprendemos com a disciplina de DevOps do SRE é que 100% de confiabilidade não é apenas irrealista, mas muitas vezes muito caro para ser realizado. O SRE estabelece o conceito de objetivos de nível de serviço (SLOs) e orçamentos de erros para quantificar a tolerância aceitável ao risco em sistemas de produção. O mesmo princípio se aplica aos testes e à qualidade geral. Veja meu blog relacionado para saber mais sobre esse assunto
Algumas validações são difíceis de executar em ambientes de teste
Isso inclui testes de desempenho em grande escala quando os ambientes de teste não são dimensionados (ou configurados) adequadamente em relação aos ambientes de produção.
Outro exemplo são os testes destrutivos ou de caos. Embora seja possível executar testes de caos isolados em ambientes de teste usando técnicas como virtualização de serviços (para simular falhas em componentes dependentes), é difícil executá-lo para ensaios destrutivos em larga escala. Por exemplo, a Netflix faz uma quantidade significativa de seus testes na produção.
Da mesma forma, o monitoramento corporativo para coletar informações sobre padrões de uso e falhas do mundo real só é possível na produção. Embora defendamos ativar o monitoramento em ambientes de teste (como parte do shift-left), esse monitoramento só ajuda a fazer monitoramento localizado (por exemplo, do aplicativo ou sistema específico que está sendo testado), e isso também em condições de teste. No entanto, os cenários de teste de desempenho que foram desenvolvidos pelos testadores podem ser reutilizados na produção (shift-right) como monitores sintéticos para medir o desempenho e a regressão do aplicativo.
Por fim, como uma extensão do monitoramento, o teste de alguns aplicativos baseados em IA pode ser difícil sem acesso aos dados de produção. Alguns algoritmos de aprendizado de máquina, por exemplo, precisam ser constantemente refinados com base em dados do mundo real. Embora esses algoritmos sejam desenvolvidos usando um conjunto limitado de dados de treinamento e teste, eles precisam ser monitorados e ajustados, com base em seu desempenho na produção.
Desenvolvedores e testadores precisam de feedback mais fácil de ciclo fechado da produção
O feedback de loop fechado mais fácil das operações permite que desenvolvedores e testadores entendam melhor o comportamento do aplicativo, prevejam o sucesso/falha das versões e respondam a incidentes de produção (por exemplo, reduzir o MTTR).
A interpretação e o uso de dados volumosos de produção são muitas vezes difíceis e tediosos para as equipes de desenvolvimento e teste. O uso de técnicas shift-right permite que desenvolvedores e testadores acessem dados de produção mais facilmente em um formato que seja facilmente consumível e acionável, aproveitando os insights certos das disciplinas AIOps. Essa colaboração de dados é um princípio fundamental do paradigma DevOps. Por exemplo, monitores sintéticos (que normalmente são criados por desenvolvedores e testadores nos estágios de desenvolvimento/teste) fornecem meios para que os desenvolvedores obtenham feedback de monitoramento em um formulário com o qual estejam familiarizados.
Além disso, a análise automatizada de causa básica de defeitos/incidentes na produção pode fornecer aos desenvolvedores e testadores informações sobre padrões e tendências de falhas, suas fontes (quando os dados de produção estão correlacionados com os dados de desenvolvimento) e o que os está causando e como eles podem ser melhor prevenidos.
Da mesma forma, cenários de uso de dados (por exemplo, de logs de banco de dados e pares RR de logs de transações de serviço) podem ser usados para geração de dados de teste relevantes.
Em essência, as práticas de teste shift-right são necessárias para criar um ciclo de feedback contínuo da experiência real do usuário com um aplicativo de produção de volta ao processo de desenvolvimento e teste.
A Evolução da Disciplina TestOps
Está claro pelos dados da pesquisa com clientes e pelos drivers discutidos acima que há uma evolução em direção a práticas de mudança para a direita.
Assim como fizemos com os testes shift-left, para tornar essas práticas sustentáveis e perceber os benefícios, precisamos também evoluir casos de uso de testadores, habilidades, ferramentas e padrões de colaboração com pessoas e disciplinas à direita do ciclo de vida do aplicativo, ou seja, operações. Em outras palavras, uma nova disciplina precisa ser estabelecida — chamamos essa nova disciplina de TestOps — uma subdisciplina dentro do contexto mais amplo de DevOps.
Embora o termo TestOps (como todas as subdisciplinas X-Ops dentro do DevOps) implique a colaboração entre testes e operações, não se trata simplesmente de deslocar para a direita. Por que? Porque com o DevOps, as próprias disciplinas operacionais mudaram para a esquerda (como deslocamento para a esquerda do monitoramento, gerenciamento de configuração, SRE, etc.). Portanto, TestOps — fiel ao princípio de teste contínuo — refere-se a uma melhor colaboração com as disciplinas de operações em todo o ciclo de vida do DevOps.
Vamos considerar algumas das principais práticas no TestOps shift-left (consulte a Figura 4).
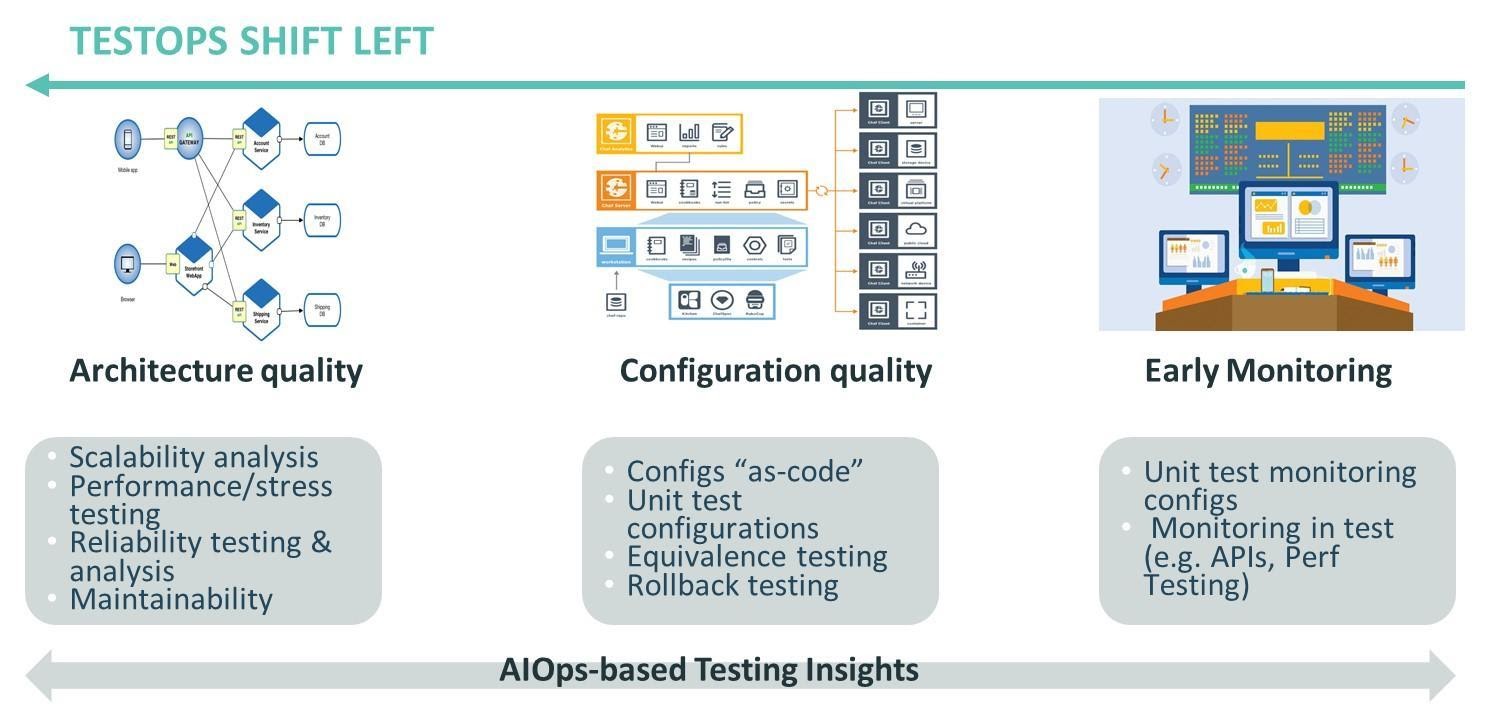
Gráfico 4.
- Testes iniciais de confiabilidade: isso inclui análise de escalabilidade estática da arquitetura do sistema, bem como testes de desempenho e estresse.
- Qualidade e teste de configuração: isso inclui testes de configurações de ambiente e implantação “as-code” (qualquer coisa “como código” pode e deve ser testada como tal, assim como o código do aplicativo), bem como testes de implantação (para testar a correção das implantações) e testes de reversão (para garantir que as reversões possam ser feitas rapidamente e com sucesso).
- Monitoramento antecipado: inclui o monitoramento de sistemas no início do ciclo de vida (por exemplo, em ambientes de desenvolvimento e teste), bem como o desenvolvimento e teste de monitores sintéticos antes de serem implantados na produção.
- Insights iniciais do AIOps: isso inclui o uso antecipado de técnicas AIOps (nos ambientes de desenvolvimento/teste) para obter testes e insights de qualidade, por exemplo, para previsão de risco de defeitos e liberações.
Abaixo estão algumas das principais práticas de deslocamento para a direita do TestOps (consulte a Figura 5).
- Engenharia do caos: isso inclui testar a confiabilidade do sistema por meio da injeção de cenários de falha controlada.
- Teste A/B: consiste em um experimento randomizado com duas (ou mais) variantes para estudar quais são mais eficazes com os usuários.
- Canary releases: consiste em técnicas usadas para reduzir o risco de introduzir uma nova versão de software em produção, implementando gradualmente a mudança para um pequeno subgrupo de usuários, antes de implementá-la em toda a plataforma/infraestrutura e disponibilizá-la para todos.
- Monitoramento sintético: inclui técnicas de monitoramento usando uma emulação ou gravações de script de transações (que refletem o comportamento típico do usuário).
- Testes e análises de CX: incluem a extração de dados de CX para entender a experiência do cliente, bem como para obter insights a partir dela (como problemas do cliente, novos requisitos de recursos, etc.).
- Outros testes em produção: inclui testes de desempenho e testes de aplicativos baseados em IA.
- Testando insights de dados de AIOps: conforme descrito acima, uma rica variedade de insights de teste pode ser obtida a partir de dados de operações.
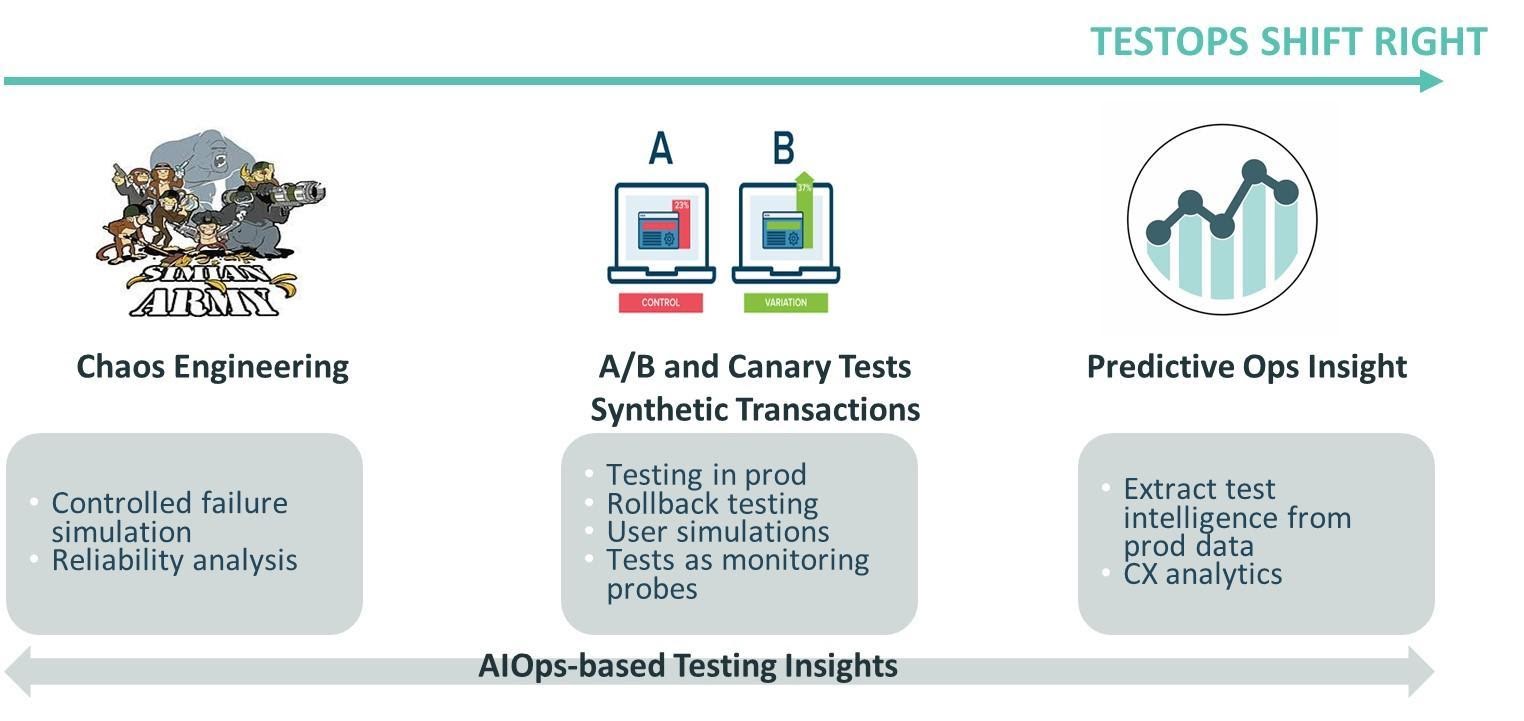
Gráfico 5.
Principais habilidades e ferramentas de TestOps
Vamos considerar as novas habilidades necessárias para as principais práticas de TestOps. Isso inclui o seguinte:
- Habilidades de análise de dados: Como a maioria dos dados de produção é volumosa, diversificada e muitas vezes temporal, os testadores agora devem coletar análises de dados para que obtenham rapidamente insights desses dados, bem como executar correlações com outros conjuntos de dados para identificar ações. Habilidades avançadas de análise (como análise preditiva ou aprendizado de máquina) também são necessárias para prever eventos (por exemplo, qualidade da versão). Embora essas habilidades de análise sejam bem compreendidas dentro da comunidade de operações (com a crescente adoção de AIOps), elas são relativamente novas para desenvolvedores e testadores.
- Habilidades de CX: Como discutimos, CX é agora considerado uma métrica chave para medir a qualidade na produção. Novos tipos de testes de CX incluem testes A/B e canários, bem como testes de multidão. Como outros dados operacionais, os dados CX também são tipicamente volumosos e muitas vezes não estruturados. Embora as equipes de CX se especializem em tais princípios, os testadores precisam adquirir habilidades suficientes para obter insights do processo e dos dados de CX e colaborar efetivamente com essas equipes.
- Habilidades de monitoramento e operações: A compreensão dos princípios de monitoramento (por exemplo, criação, teste e implantação de monitores e uso de dados de monitores) é uma habilidade fundamental necessária para o TestOps. Da mesma forma, os testadores também devem entender os princípios de operações (incidentes, falhas, alarmes, MTBF, MMTR, definições de configuração, etc.) para que tais informações possam ser aproveitadas para fins de teste, bem como para colaboração com equipes operacionais.
- Habilidades de confiabilidade: A confiabilidade também é outro atributo chave de qualidade operacional com o qual os testadores precisam estar familiarizados. Isso inclui testes de caos/resiliência, testes de implantação e reversão e testes de configuração. A disciplina de SRE evoluiu dentro do DevOps para abordar a confiabilidade, e muitos de seus princípios se sobrepõem ao TestOps.
- Novas habilidades em ferramentas: Além de usar ferramentas de teste tradicionais, o TestOps também requer o uso de ferramentas adicionais, como monitoramento, análise de dados (para dados de produção e CX), testes de CX (como testes A/B e canários) e testes de confiabilidade. As inovações tecnológicas que suportam testadores com esses novos recursos incluem RunScope (uma ferramenta leve de monitoramento de API que pode ser usada para monitoramento em ambientes de teste e produção), Blazemeter (para testes de desempenho para CX e confiabilidade), Optimizely para testes A/B. Para análise de dados, tecnologias como a automation.ai simplificam o trabalho de agregação e modelagem de dados para que os testadores possam extrair mais facilmente insights acionáveis dos dados coletados em todo o ciclo de vida.
Principais colaborações TestOps
Além de novas habilidades, os testadores agora devem aprender a colaborar melhor com outras partes interessadas, como mencionado acima. Estes incluem:
- Colaboração com engenheiros de ciência de dados e IA/ML: Isso é necessário para que os testadores ajustem ou criem novos algoritmos e modelos necessários para executar as análises necessárias para o TestOps.
- Colaboração com engenheiros e equipes de CX: Isso é necessário para que os testadores monitorem as métricas e os dados de CX apropriados e estudem o impacto de suas atividades de teste/controle de qualidade na CX.
- Colaboração com engenheiros e equipes de Operações: Isso é fundamental para que o TestOps não apenas ofereça suporte a todas as atividades de teste de turno direito, mas também obtenha acesso aos dados de produção necessários para a análise do TestOps. Isso é análogo a como os testadores colaboram com os desenvolvedores como parte do shift-left.
- Colaboração com SREs: Como mencionado, há um grau razoável de sobreposição entre os princípios SRE e TestOps e, portanto, a colaboração com SREs é fundamental para os testadores. Veja meu blog sobre como testadores e SREs podem trabalhar melhor juntos para melhorar a confiabilidade.
Conclusão
Esperançosamente, este artigo forneceu aos leitores algumas informações sobre a disciplina emergente do TestOps. À medida que construímos microsserviços cada vez mais distribuídos e sistemas nativos da nuvem, e à medida que a disciplina de SRE amadurece, esperamos ver mais práticas de teste de mudança para a direita que enriquecem o TestOps.