Como consultar (quase) tudo
Em 2022, dei uma palestra em uma conferência virtual com um nome inesquecível: HYTRADBOI, que significa “Você já tentou esfregar um banco de dados nele?” Seu objetivo era discutir usos não convencionais de tecnologia semelhante a banco de dados e contou com muitas palestras excelentes.
Minha palestra “Como consultar (quase) tudo” recebeu muitos elogios. Ele descreve a arquitetura do mecanismo de consulta Trustfall e inclui exemplos do mundo real de como meu (agora ex) empregador confia nele para capturar e evitar estaticamente bugs entre domínios em um monorepo com centenas de serviços e bibliotecas compartilhadas. Por exemplo:
- Capture os serviços do Python que especificam uma versão do Python em seu manifesto e uma versão diferente (incompatível) do Python em seu Dockerfile de implantação.
pyproject.toml - Capture bibliotecas Python que especificam dicas de tipo, mas cuja configuração de CI desabilitou a verificação de tipo, o que significa que as dicas de tipo incluídas podem estar incorretas.
mypy
O conteúdo da palestra ainda é relevante hoje, com a Trustfall agora alimentando ferramentas como verificações de carga. E até onde eu sei, meus ex-colegas de trabalho ainda estão felizes usando tudo o que foi descrito na palestra! $^1$ Espero que gostem!
Você pode assistir ao vídeo da palestra no site da conferência, no YouTube ou incorporado abaixo. Continue lendo para obter uma versão anotada da palestra, $^2$ cobrindo as mesmas ideias na forma escrita.
Contorno
- Problema: Consultar dados que não são de banco de dados é difícil
- Agenda: Consultar tudo é valioso e mais fácil do que parece
- Nunca depurar o mesmo problema duas vezes
- Noções básicas de consulta de tudo
- Demonstração: Quais GitHub Actions são usados em projetos populares no HackerNews?
- Como a Trustfall executa consultas
- Por que conectar um novo conjunto de dados é fácil
- Nós apenas arranhamos a superfície!
Problema: Consultar dados que não são de banco de dados é difícil
Pule para este capítulo do vídeo.
Estamos em uma situação engraçada hoje em dia: consultas triviais em um banco de dados SQL são dolorosamente difíceis em relação a qualquer outra fonte de dados.
Deixe-me dar um exemplo.
Quais GitHub Actions são usados em projetos populares no HackerNews?
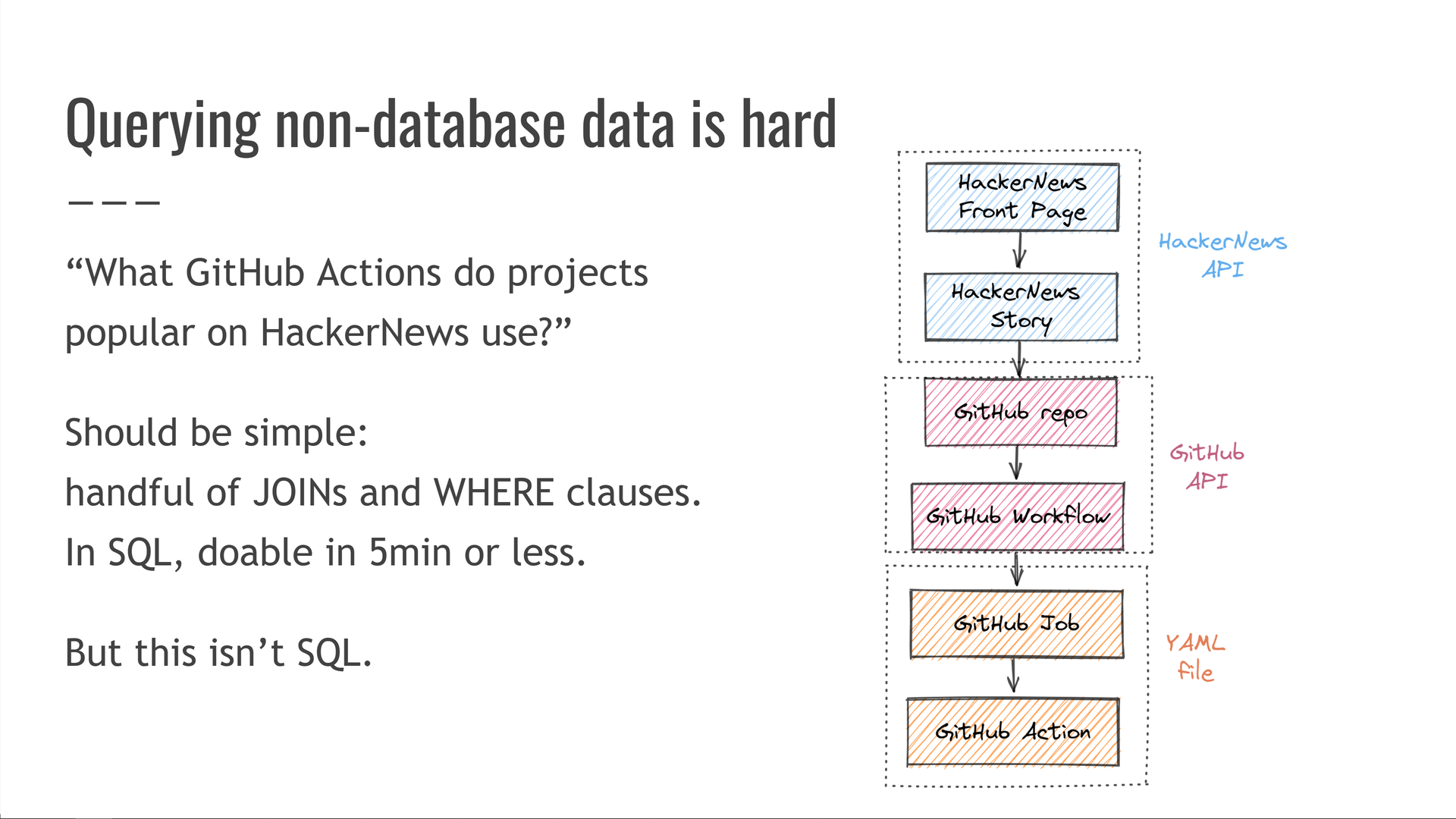
Em princípio, isso deve ser simples! Se tivéssemos esses dados em um banco de dados SQL, essa consulta seria apenas um punhado de cláusulas e — devemos ser capazes de escrevê-la em apenas alguns minutos.JOINWHERE
Mas não temos esses dados em SQL. Em vez disso, temos que fazer um link cruzado entre a API HackerNews, a API do GitHub e um formato de arquivo YAML personalizado do GitHub Actions.
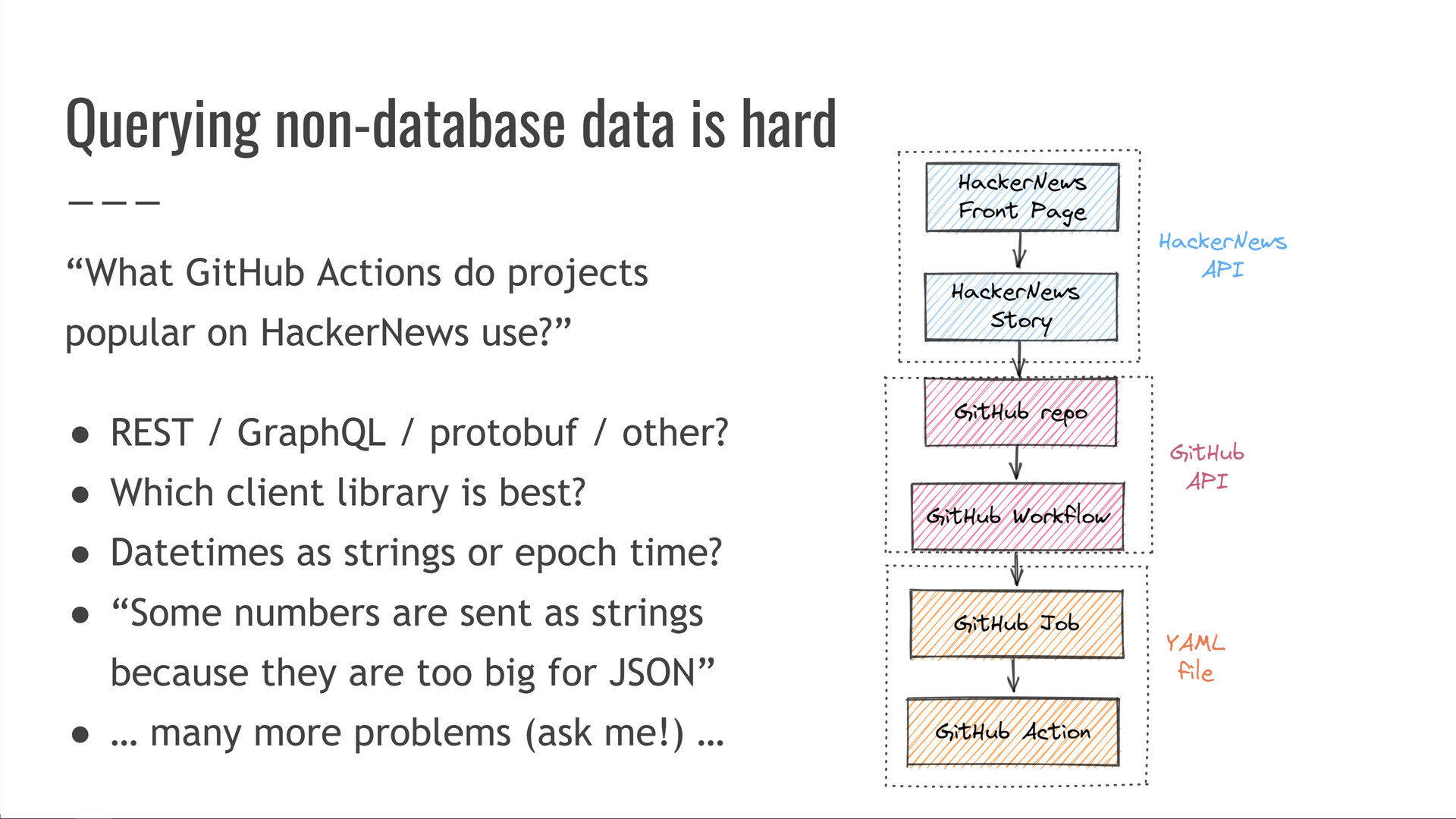
Então temos que nos preocupar com coisas como:
- Como a API é estruturada? É REST / GraphQL / protobuf / outra coisa?
- Qual biblioteca de cliente é melhor para minha linguagem de programação?
- As datas/hora são representadas como strings RFC 3339 ou segundos desde a época?
- Às vezes, os números são enviados como strings porque podem ser muito grandes para o formato de dados, como inteiros de 64 bits em JSON?
E ainda nem chegamos a executar a consulta!
O resultado final é que essa consulta se torna tão irritantemente difícil que pode não valer a pena fazê-la.
Agenda: Consultar tudo é valioso e mais fácil do que parece
Pule para este capítulo do vídeo.
Nesta palestra, quero convencê-lo de duas coisas.

Primeiro, que consultar quase tudo é super valioso. Para isso, vou mostrar-lhe um estudo de caso com o meu antigo $^3$ empregador, Kensho.
Em segundo lugar, que consultar quase tudo é muito fácil! Para isso, mostrarei uma demonstração da consulta de que acabamos de falar.
Nunca depurar o mesmo problema duas vezes
Pule para este capítulo do vídeo.
Na Kensho, descobrimos que depurar o mesmo problema repetidamente é uma grande perda de tempo. Decidimos resolver isso.

Depurar o mesmo problema mais de uma vez é o subproduto de muitos desafios sociais e de engenharia que tivemos que superar.

Os sistemas falham de maneiras complicadas, as pessoas esquecem as coisas, etc. Não é óbvio como usar “a equipe A depurou algo” para evitar que a equipe B tenha que depurar a mesma coisa no futuro.
Isso requer ter uma memória institucional perfeita em toda a empresa, para sempre.

Nossa solução é consultar recorrências de problemas conhecidos e, em seguida, evitá-los.
Temos consultas procurando cerca de 40 problemas conhecidos. $^4$ Também continuamos adicionando uma a duas novas consultas por semana.
Cada vez que alguém abre uma solicitação pull, verificamos seu código com todas essas 40 consultas. Isso leva cerca de ~ 0,3s, embora não tenhamos feito muito trabalho de otimização para reduzir ainda mais esse número.

Esse terço de segundo em tempo extra de CI evitou inúmeras horas de serem desperdiçadas na depuração.
Ainda mais importante, detectar problemas mais cedo libera recursos de infraestrutura e SRE! Isso é um pouco sutil, então tenha paciência comigo: digamos que você tenha uma dúzia de equipes implantando serviços em produção. Então, um desses serviços sofre um incidente de estímulo - quem arca com o custo de resolvê-lo? A equipe que é dona do serviço, mas também as equipes de infraestrutura e SRE!
Agora estenda isso ao longo de meses: diferentes serviços sofrem incidentes, mas a infraestrutura e o SRE arcam com um custo a cada vez, enquanto o restante da carga é distribuído por diferentes equipes.
Essa ferramenta reduz o número de incidentes de produção capturando o código com bugs mais cedo e impedindo que ele seja mesclado e implantado. Embora cada equipe proprietária de serviços seja um pouco mais rápida e feliz, as equipes de infraestrutura e SRE experimentam um enorme efeito positivo: elas são paginadas e interrompidas com menos frequência, têm mais ciclos para enviar melhorias adicionais e também são mais felizes! Isso configura um glorioso ciclo de feedback positivo: infra e SRE têm mais ciclos, levando a mais atualizações de infraestrutura e mais verificações, o que, por sua vez, diminui ainda mais os incidentes e leva a ainda mais ciclos para todos!
Também descobrimos que todos podem ser bem-sucedidos em escrever consultas — nossos engenheiros, gerentes de produto e analistas também tiveram sucesso com isso.
O resultado líquido: enviamos coisas maiores, mais rápido. Como ninguém gosta de depuração, todos também ficam mais felizes! $^5$
Exemplo: incompatibilidade de versão do Python no vs pyproject.tomlDockerfile
Pule para este capítulo do vídeo.
Deixe-me dar um exemplo de como são essas consultas.
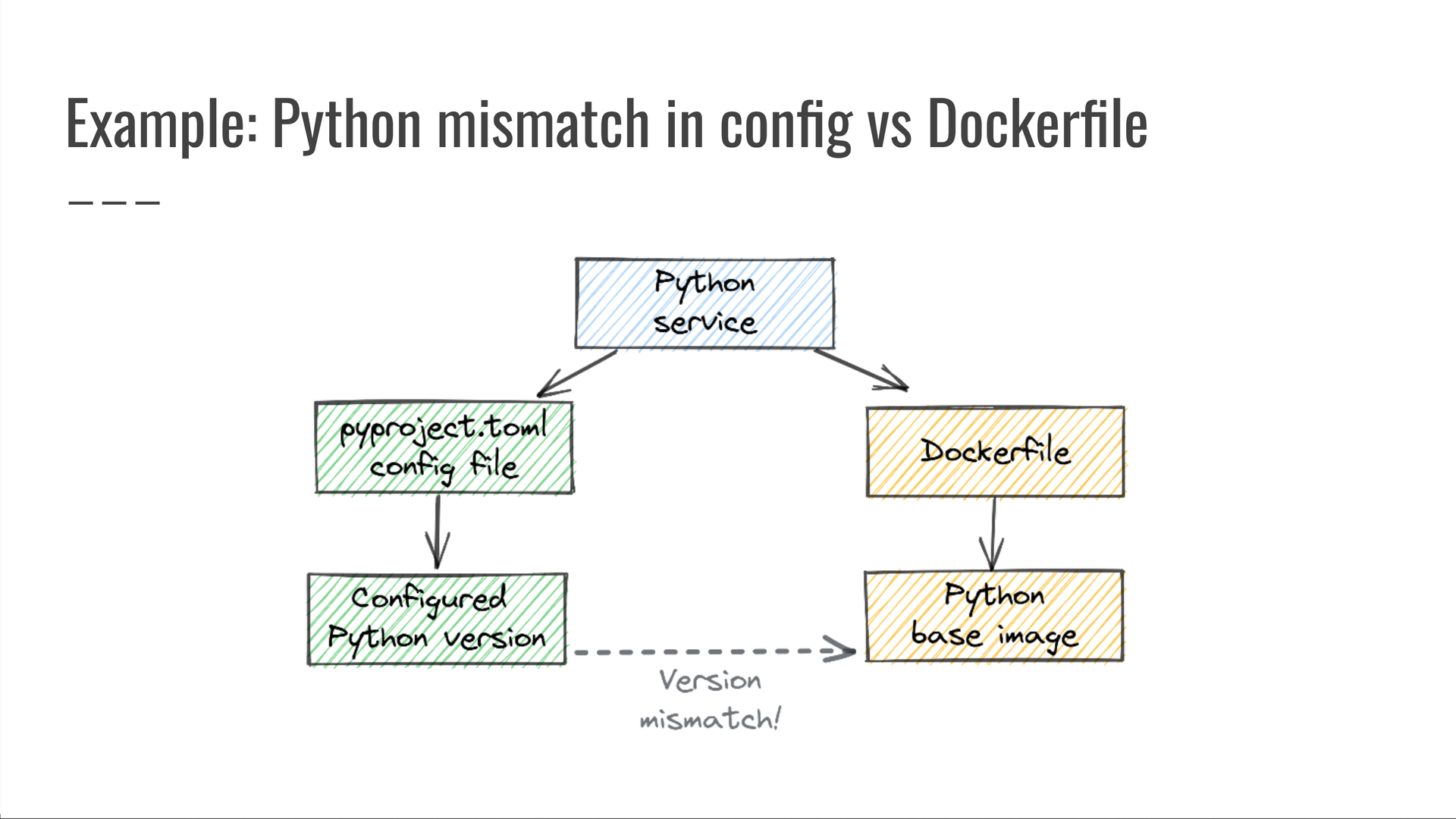
Em um ponto, tivemos que depurar uma situação em que um serviço Python foi implantado com uma versão inesperada do Python, que não correspondia à versão especificada pelo arquivo.pyproject.toml
Para evitar que tais incidentes aconteçam, escrevemos a seguinte consulta: “Procure serviços Python cujo arquivo de configuração especifica uma versão do Python, mas o usado para implantar esse serviço especifica uma versão diferente do Python”. Quaisquer resultados da execução dessa consulta foram bugs claros, que foram prontamente corrigidos e impedidos de voltar.pyproject.tomlDockerfile
Esta é uma consulta em três fontes de dados:
- os arquivos de definições de serviço do nosso monorepo, escritos em JSON;
- o arquivo de configuração do projeto baseado em TOML, e
pyproject.toml - o que controla como o serviço é implantado.
Dockerfile
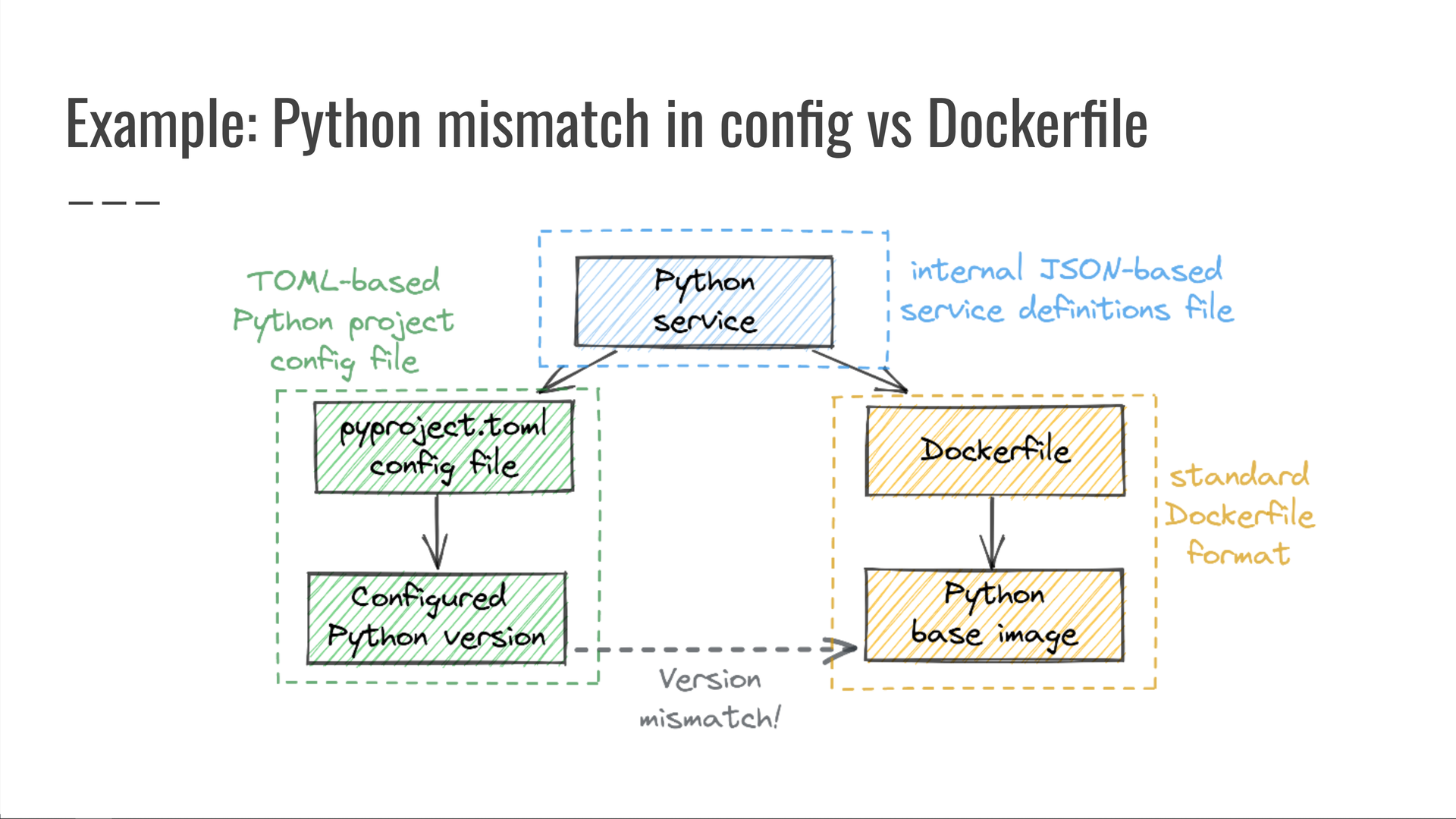
É impossível detectar esse problema sem examinar todas as três fontes de dados ao mesmo tempo! Por si só, todos eles parecem bons - uma definição de serviço válida, um arquivo normal e um arquivo .pyproject.tomlDockerfile
O problema não é com nenhum deles individualmente.
A questão é que eles não funcionarão juntos. Somente uma consulta entre domínios pode detectar isso.
Exemplo: dicas de tipo Python que nunca são verificadas
Pule para este capítulo do vídeo.
Aqui está outro exemplo:
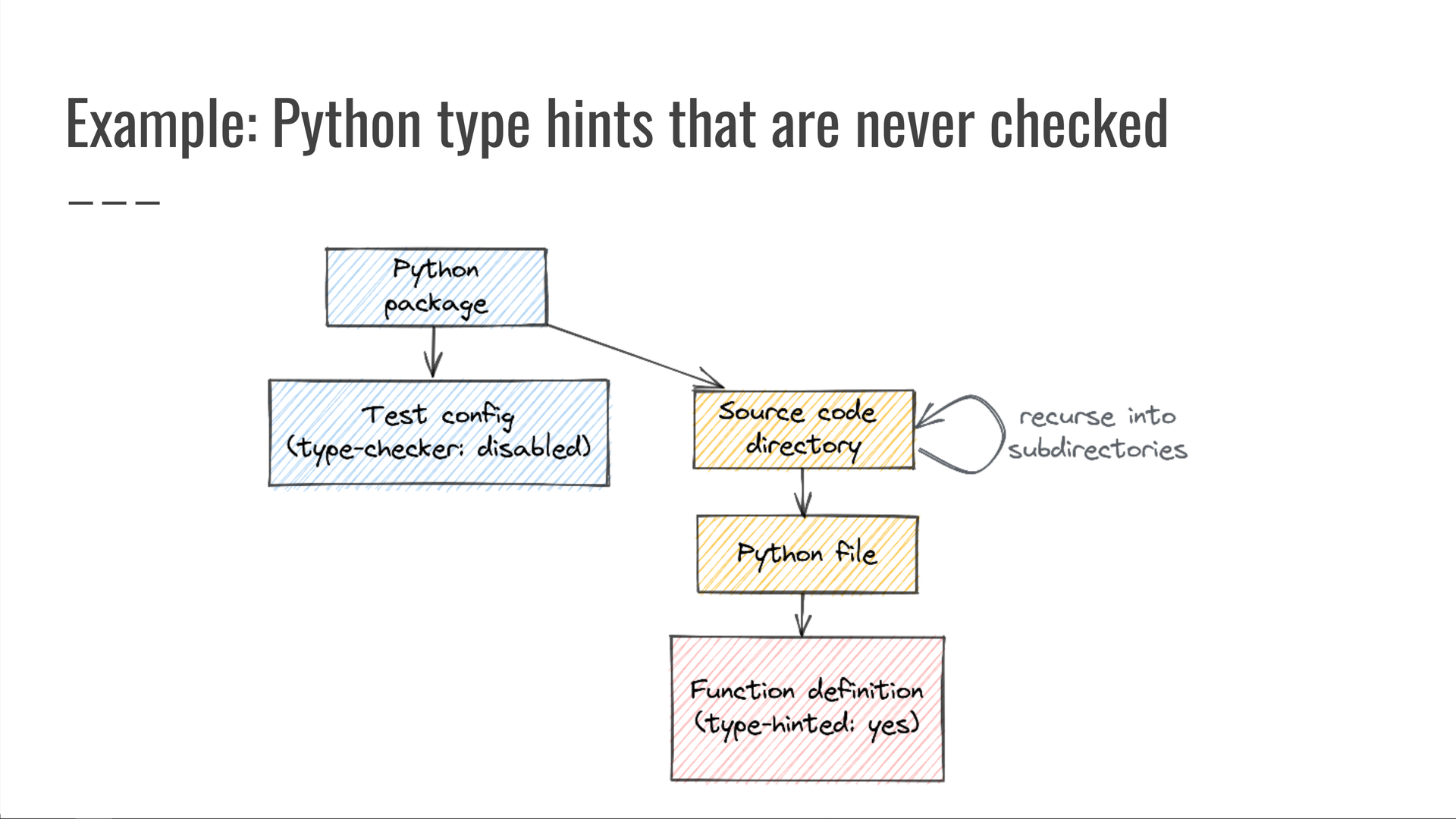
Em um ponto, tivemos que depurar um pacote interno do Python que tinha dicas de tipo incorretas, porque a configuração de CI do pacote ignorou a verificação de tipo, o que significa que as dicas de tipo nunca foram verificadas.mypy
Em seguida, escrevemos a seguinte consulta: “Procure pacotes Python cuja configuração de teste diga para não executar a verificação de tipo, mas cujo diretório de código-fonte (ou qualquer um de seus subdiretórios) inclua pelo menos um arquivo Python contendo qualquer código que especifique uma dica de tipo.” Como essas dicas de tipo são especificadas no código-fonte, mas nunca são verificadas, elas podem estar erradas — portanto, esse código não deve ser permitido.
Quaisquer resultados produzidos por essa consulta eram claramente preocupantes e trabalhamos com os proprietários de código afetados para resolvê-los e, ao mesmo tempo, evitar que essa categoria de bug ocorresse novamente.
Mais uma vez, esta é uma consulta em várias fontes de dados:
- os arquivos de definição de pacote Python do nosso monorepo;
- nosso controle do código-fonte git e dados do sistema de arquivos para as travessias de diretório e arquivo, e
- as árvores de sintaxe analisadas dos arquivos de código-fonte do Python, onde procuramos definições de itens do Python que incluem dicas de tipo.
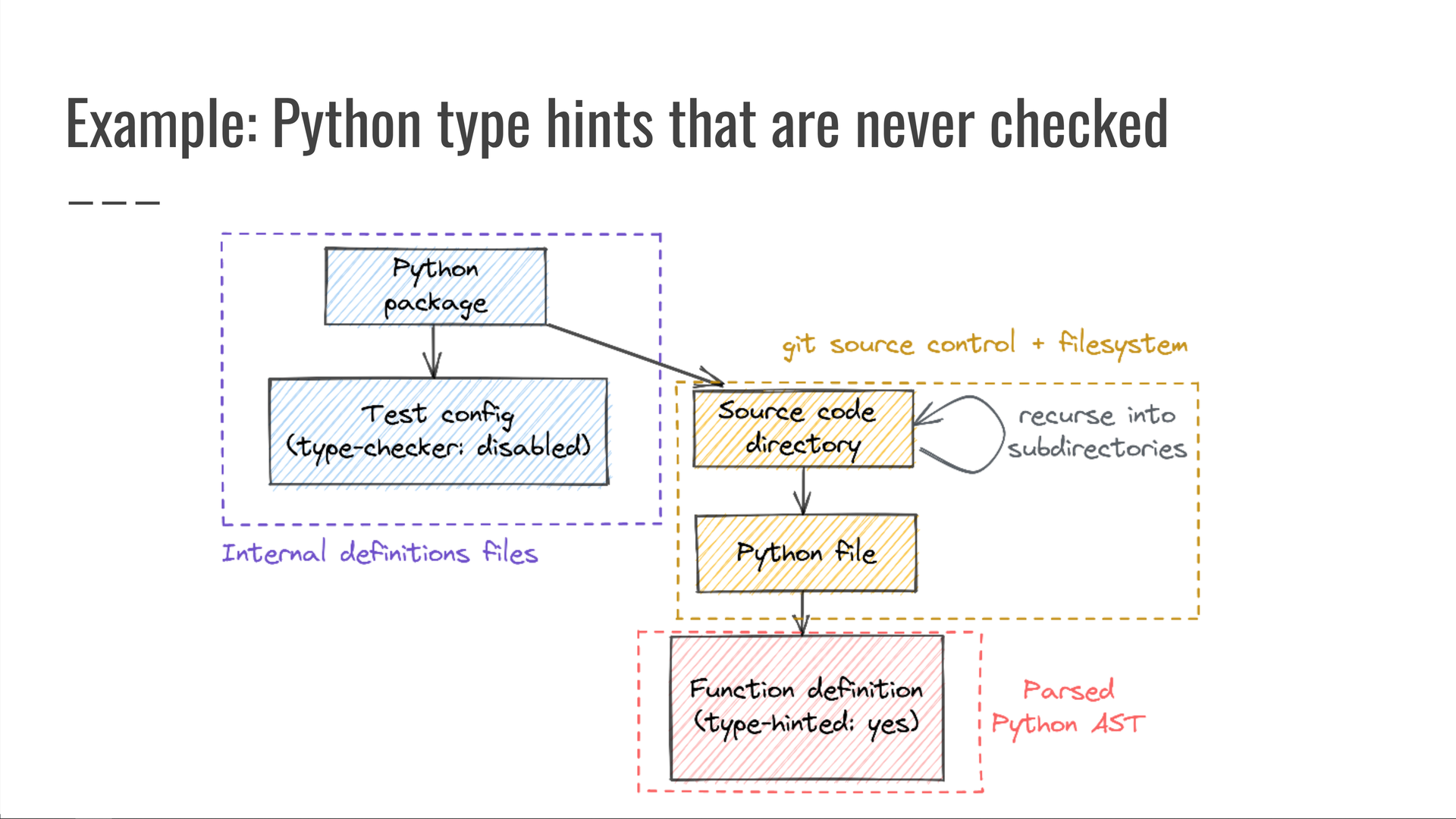
Vistos individualmente, cada um desses componentes parecia bom.
O problema só foi detectável quando considerados como um todo.
Consultas do mundo real em muitas fontes de dados são fáceis e práticas
Pule para este capítulo do vídeo.
No lançamento desta palestra em 2022, mais de uma dúzia de fontes de dados diferentes estavam disponíveis para consulta no sistema da Kensho. $^6$

Descobrimos que adicionar uma nova fonte de dados é super simples e é um ótimo projeto de integração para novos engenheiros e estagiários da equipe.
Ele também teve alguns benefícios adicionais inesperados!

Assim que ficou fácil escrever consultas como “quais pacotes internos do Python nunca são usados em nenhum serviço”, descobrimos e excluímos quase 300.000 linhas de código não utilizado em nosso monorepo! $^7$ $^8$
Noções básicas de consulta de tudo
Pule para este capítulo do vídeo.
Tendo abordado por que consultar quase tudo é útil, vamos ver como fazê-lo.
Primeiro, precisamos perceber tudo como um gráfico.

Teremos um esquema que descreve nosso conjunto de dados em termos de vértices, propriedades digitadas nesses vértices e arestas entre eles. Também teremos uma hierarquia de tipos entre os diferentes tipos de vértices, para que possamos dizer que um vértice é um tipo de .GitHubRepositoryWebpage
Isso é equivalente ao modelo relacional (SQL). Se você se sentir confortável com SQL, se sentirá em casa aqui: vértices são tabelas, propriedades são colunas, arestas são chaves estrangeiras, etc.
Veja como é o nosso gráfico “HackerNews encontra GitHub”:
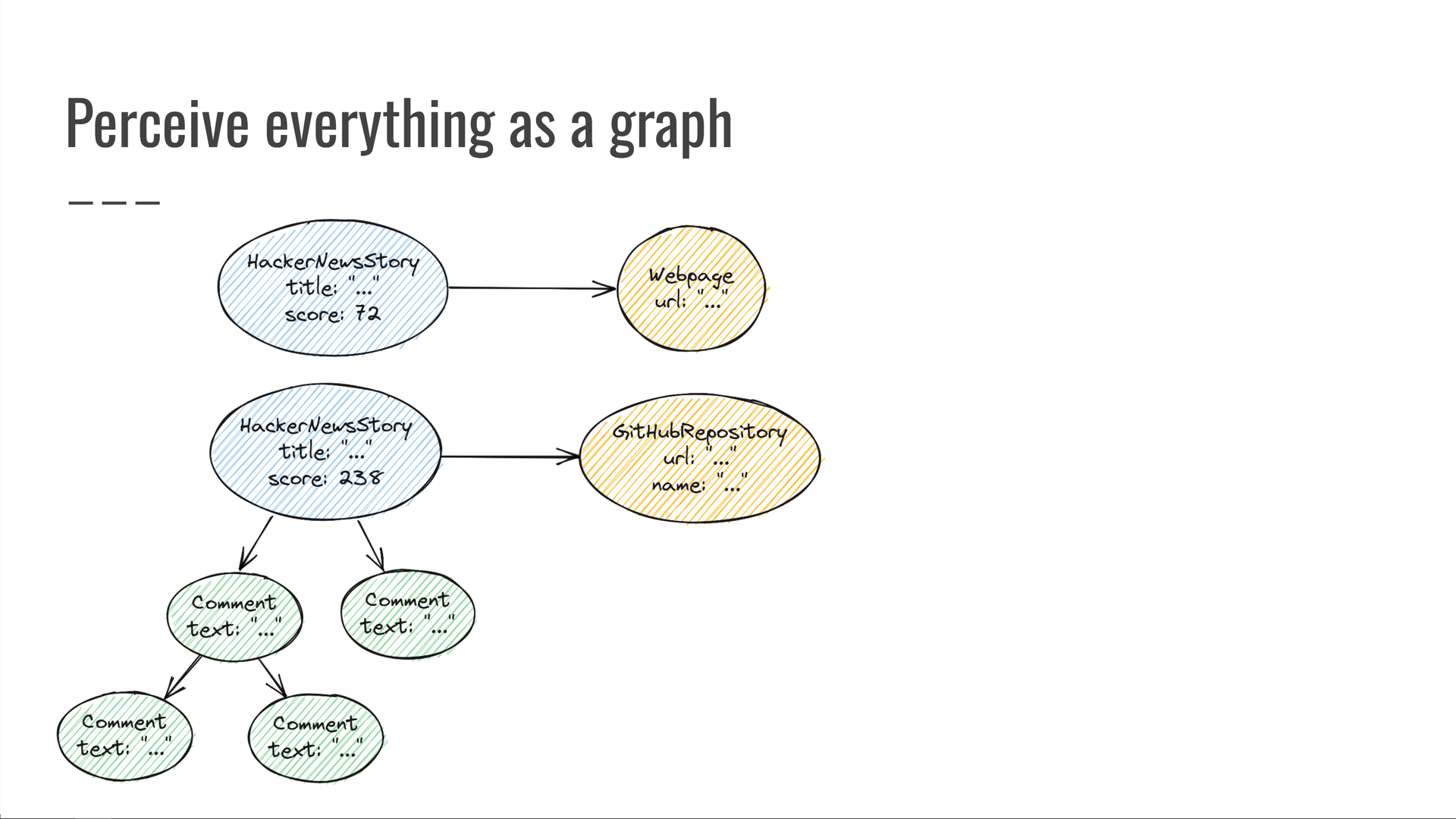
Temos algumas histórias do HackerNews com títulos e pontuações. Alguns deles têm comentários. As histórias apontam para páginas da web, algumas das quais são repositórios do GitHub e assim por diante.
Para executar uma consulta nesse gráfico, precisamos fazer duas coisas: definir um padrão a ser procurado e, em seguida, selecionar um conjunto de propriedades a serem retornadas dos vértices que correspondem ao nosso padrão.
Por exemplo, vamos procurar histórias de tendências do HackerNews com uma pontuação de pelo menos 50 pontos, que também apontam para um repositório GitHub. Para cada correspondência, digamos que queremos saber a URL do repositório GitHub e a pontuação do HackerNews de sua história.
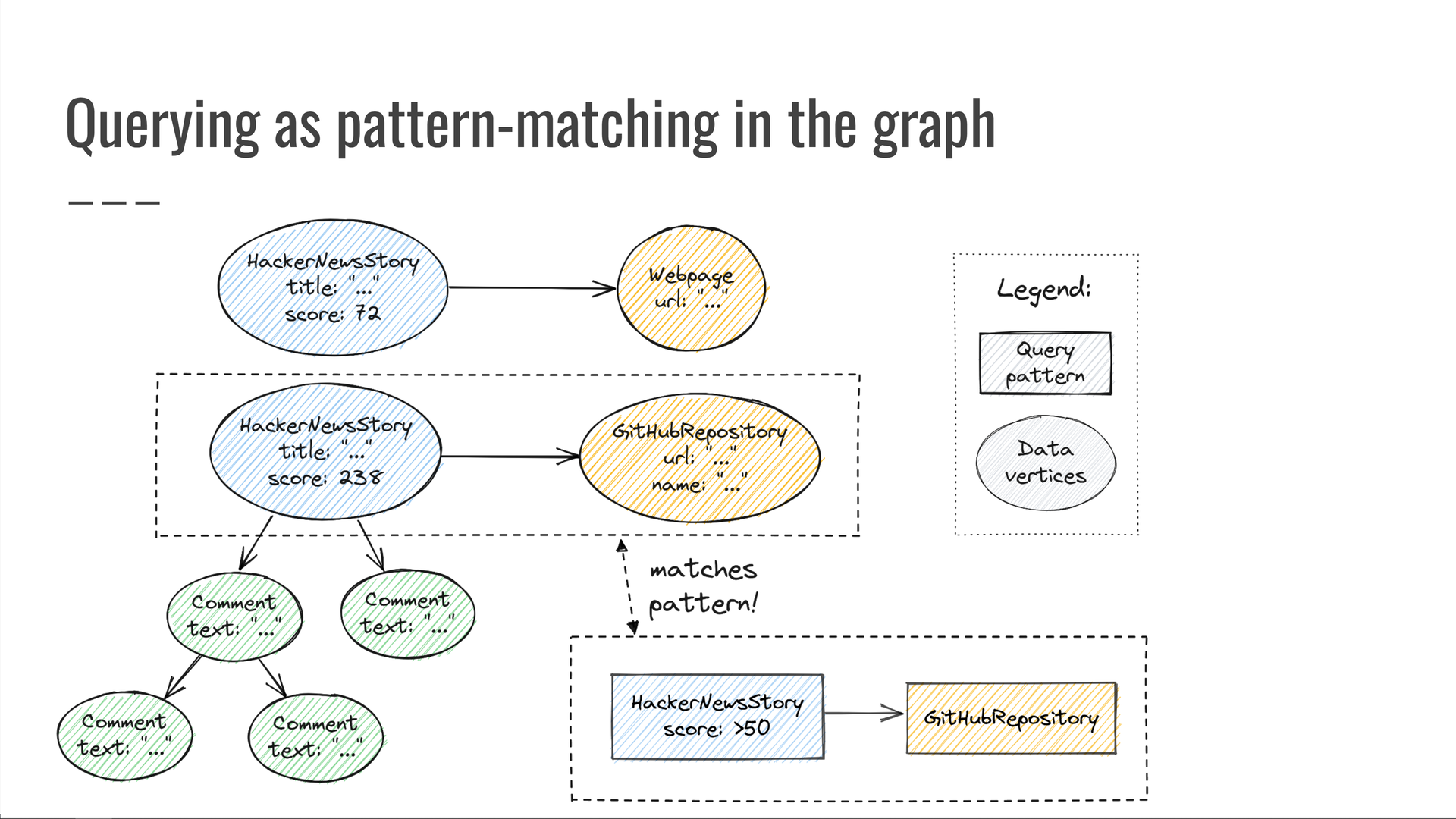
Dando uma olhada em nosso gráfico de dados, descobrimos alguns vértices que correspondem ao nosso padrão. Em seguida, produzimos os valores das propriedades nas quais estávamos interessados.
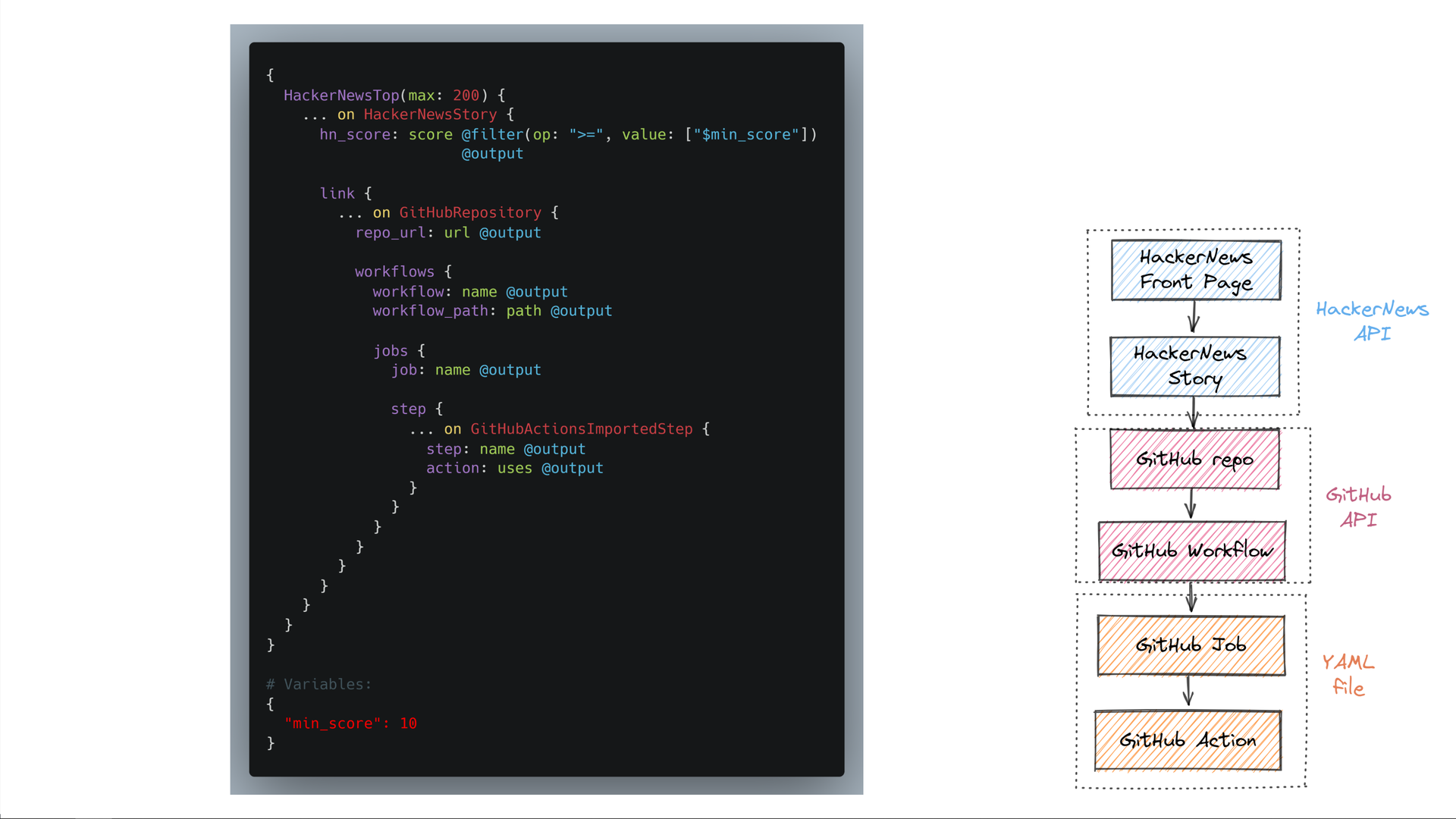
Veja como essa consulta se parece na sintaxe de consulta do Trustfall:
![The query is the following: { HackerNewsTop(max: 30) { ... on HackerNewsStory { score @filter(op: ">", value: ["$min_score"]) @output link { ... on GitHubRepository { url @output } } } } } We provide the query with the value 50 for its "min_score" variable. The "... on HackerNewsStory" clause selects only stories, discarding other kinds of HackerNews items such as job postings. The "@filter" clause applies the "greater than 50 points" predicate on the story's score. The "link" edge on HackerNews stories points to a vertex of type "Webpage", but we are only interested in the Webpage subtype "GitHubRepository" — we select only those by using the "... on GitHubRepository" clause. Since the Trustfall engine is pluggable, its front end can be swapped out to support any alternative query syntax as well.](https://predr.ag/processed_images/slide-24.b389bcec88699a1b.png)
Primeiro, começamos com os principais envios atuais no HackerNews. Então:
- Selecionamos apenas envios de histórias, descartando outros itens, como anúncios de emprego.
- Garantimos que a pontuação seja de pelo menos 50 pontos.
- Garantimos que o link da história aponte para um repositório GitHub, e não apenas para uma página da web arbitrária.
- Produzimos a pontuação e a URL do repositório.
Demonstração: Quais GitHub Actions são usados em projetos populares no HackerNews?
Pule para este capítulo do vídeo.
Vamos demonstrar o Trustfall de ponta a ponta, executando a consulta que parecia tão complicada no início da palestra!

Escrito na sintaxe Trustfall, é um pouco mais complexo do que nosso exemplo anterior - mas é apenas mais das mesmas operações que já vimos.
Mais uma vez, começamos com os principais envios no HackerNews, descartando tudo o que não é um envio de história. Filtramos a pontuação como antes. Em seguida, navegamos por todas as bordas de que precisamos até chegarmos ao GitHub Actions invocado pelos fluxos de trabalho desse repositório.
Chega de conversa - vamos vê-lo correr! (Você pode tentar você mesmo pegando o código do GitHub!)

Clique para reproduzir a animação acima
Em apenas alguns segundos, nossa consulta executou com sucesso dezenas de solicitações nas APIs do HackerNews e do GitHub em nosso nome e retornou todos os dados solicitados. $^9$
Vamos dar uma olhada mais profunda nos dados que obtivemos.
Primeiro, vemos que obtivemos dados para vários repositórios diferentes do GitHub, cada um dos quais obteve um número diferente de pontos no HackerNews.
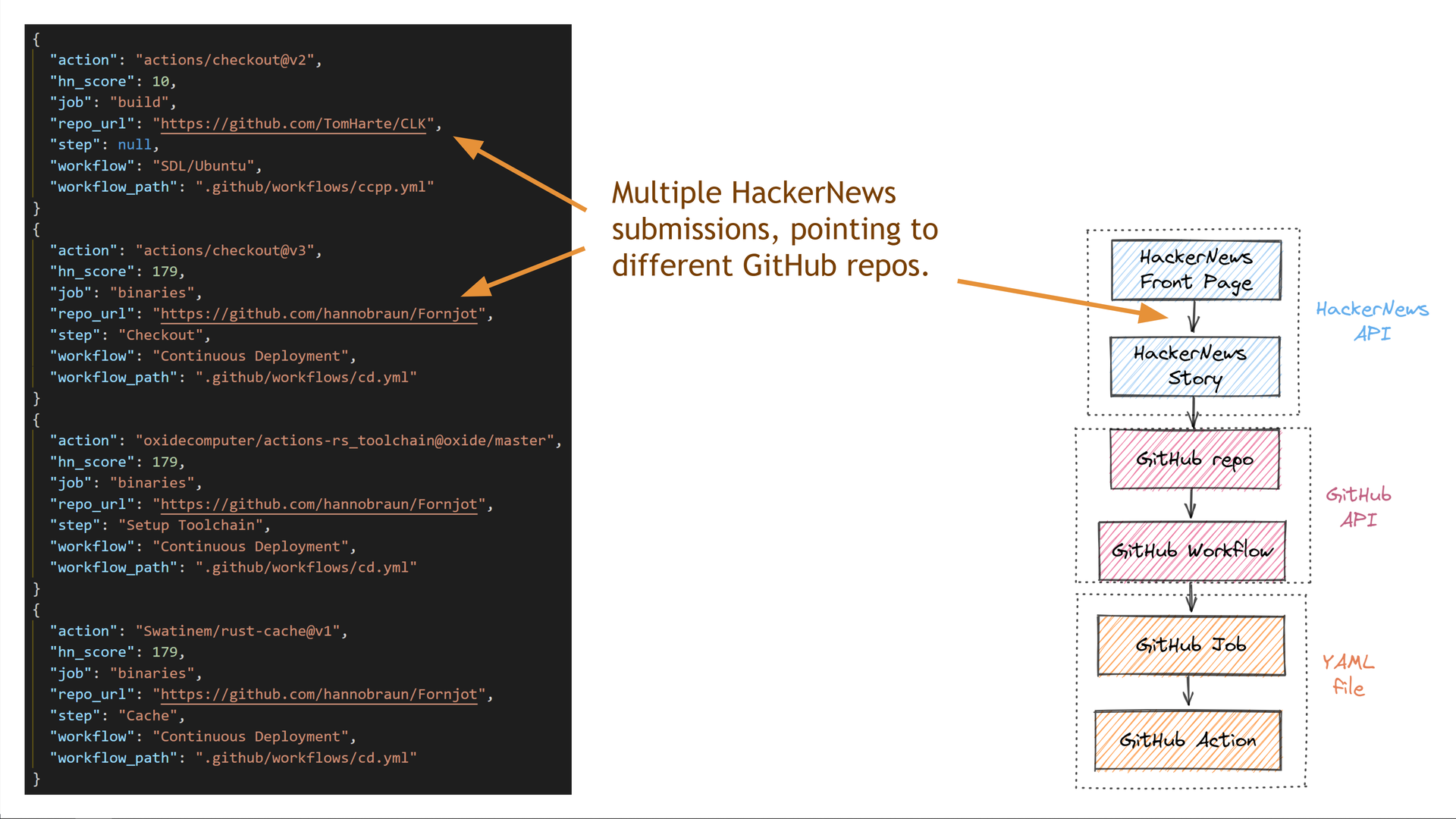
Alguns dos repositórios têm vários trabalhos no mesmo arquivo de fluxo de trabalho do GitHub Actions.

Alguns repositórios também têm vários arquivos de fluxo de trabalho diferentes.

A diversidade nos dados retornados mostra como nossa consulta capturou com êxito a semântica do domínio que estávamos consultando.
Como a Trustfall executa consultas
Pule para este capítulo do vídeo.
A melhor maneira de pensar sobre o Trustfall é que ele é como “LLVM para bancos de dados”. Ele é estruturado como um compilador tradicional:
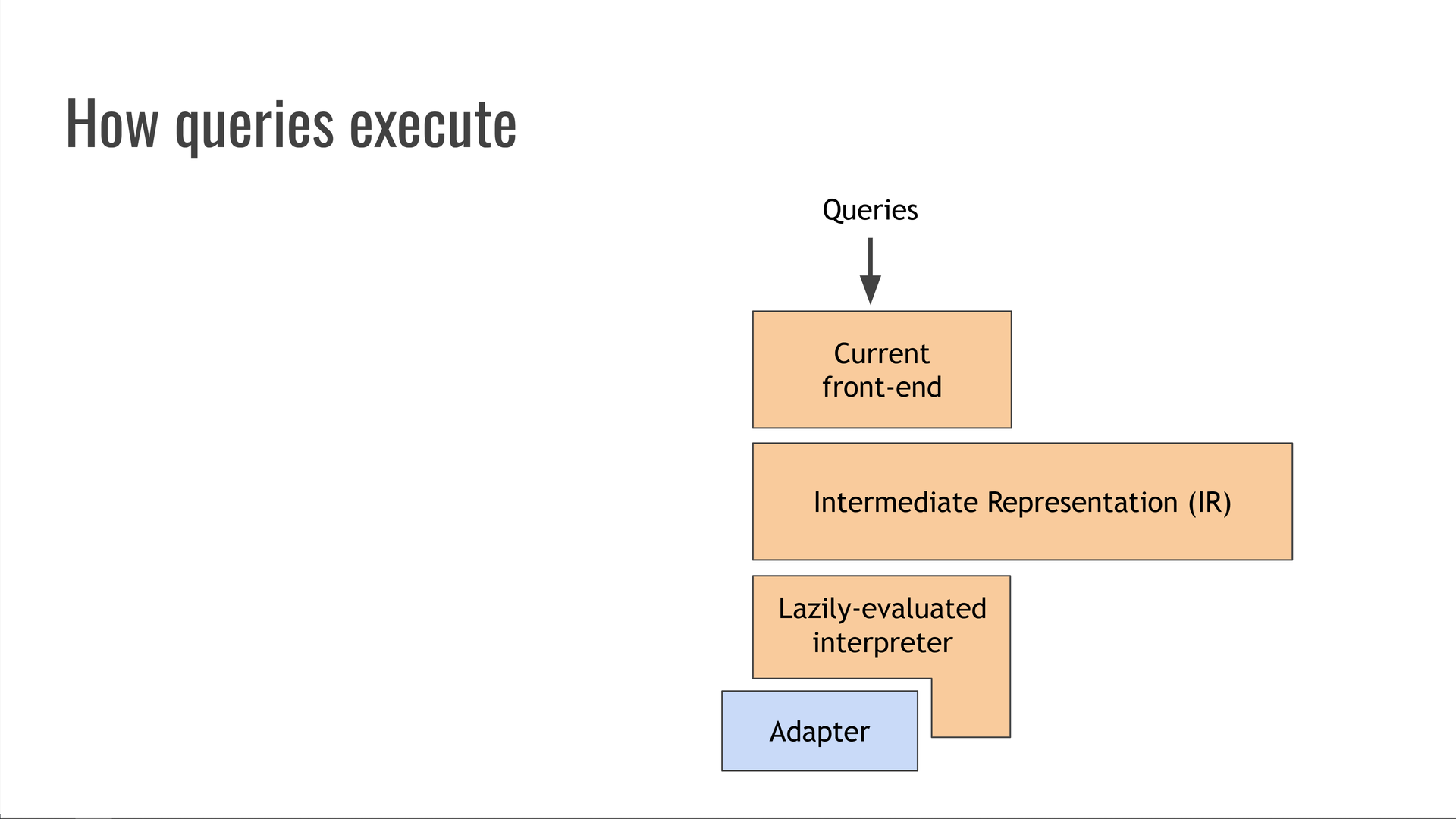
As consultas de entrada são lexadas, analisadas e convertidas em IR (representação intermediária) no front-end do compilador.
O IR representa a consulta sem estar vinculado à sintaxe original nem a uma fonte de dados específica ou à maneira de executar essa consulta.
Atualmente, o IR é executado por um intérprete preguiçosamente avaliado. Tradicionalmente, isso é chamado de “back-end” do compilador, pois consome IR e se comunica com um sistema subjacente.
O Trustfall é um sistema de segunda geração e uma reescrita em Rust de seu antecessor baseado em Python, o compilador graphql, que foi amplamente utilizado na Kensho por muitos anos. Esta postagem do blog da Kensho mostra alguns dos recursos do : ele pode compilar diretamente para várias linguagens de consulta de banco de dados diferentes, como OrientDB MATCH e os dialetos SQL para Postgres, Oracle e Microsoft SQL Server. Seus back-ends também suportavam estimativa de custos de consulta, paralelização e paginação automáticas de consultas e muitos outros truques interessantes.graphql-compiler
Infelizmente, ser um projeto Python bastante antigo (originalmente iniciado no Python 2!) significava que a base de código havia acumulado um pouco de dívida técnica. Reescrevê-lo em Rust sob o nome Trustfall ofereceu uma oportunidade de revisitar antigas decisões de design com quase 10 anos de retrospectiva e melhorar substancialmente a capacidade de manutenção e o desempenho no processo.graphql-compiler
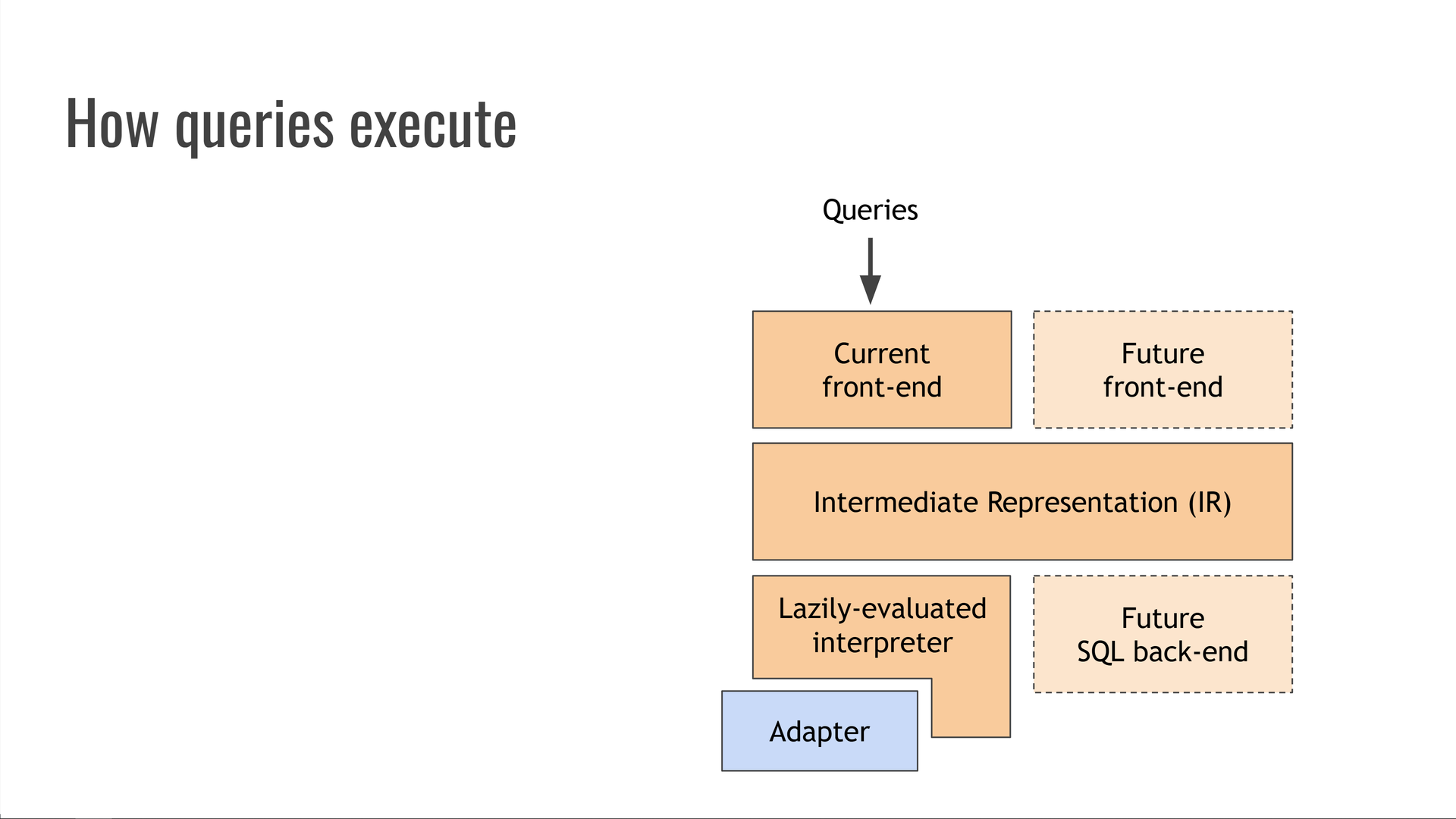
Embora a Trustfall atualmente não implemente todos os sinos e assobios do , seu design é capaz de suportá-los no futuro. Poderíamos adicionar front-ends alternativos para aceitar diferentes linguagens de consulta, como GraphQL ou SQL. Também podemos adicionar back-ends alternativos, como aqueles que executam consultas compilando-os primeiro no SQL.graphql-compiler
Portanto, como um LLVM para bancos de dados.
Por que conectar um novo conjunto de dados é fácil
Pule para este capítulo do vídeo.
Todos os componentes que descrevemos até agora são completamente independentes da fonte de dados específica que fornece os dados para nossas consultas. Eles são consideráveis - dezenas de milhares de linhas de código - mas são “escreva uma vez, use em qualquer lugar!”
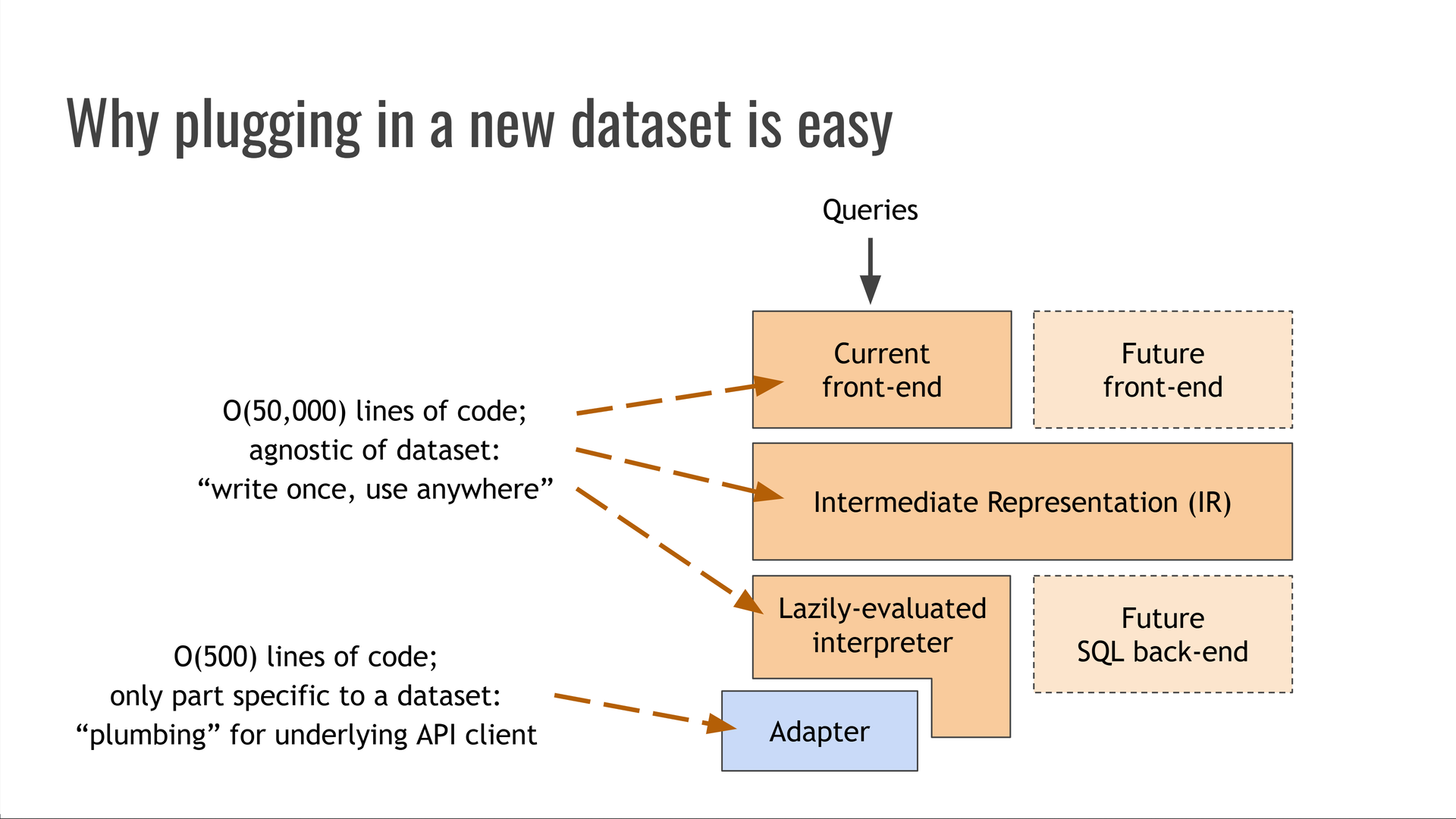
O único componente que não é independente do conjunto de dados é o módulo adaptador, que atua como encanamento entre o interpretador e a API subjacente ou o formato de arquivo de dados que contém os dados que estão sendo consultados.
O adaptador é um código muito menor e mais simples do que o próprio Trustfall - geralmente, apenas algumas centenas de linhas de código. Ele fornece um esquema — os tipos de vértices, propriedades e bordas do conjunto de dados — que geralmente pode ser gerado automaticamente, por exemplo, a partir de um esquema de banco de dados ou de uma especificação OpenAPI. $^10$
Em seguida, o adaptador implementa quatro funções que abrangem operações nesse esquema:
- Resolva o “ponto de entrada” de uma consulta, obtendo um conjunto inicial de vértices para trabalhar. Por exemplo: buscar os envios atuais mais bem classificados no HackerNews.
- Resolva o valor de uma propriedade específica em um vértice, como obter a pontuação de um envio do HackerNews.
- Resolva uma aresta, começando em um vértice e obtendo seus vértices vizinhos ao longo dessa aresta. Por exemplo, obter o vértice (se houver) para o qual uma história do HackerNews aponta.
Webpage - Resolva uma relação de subtipagem de vértice análoga ao operador do Python, como responder “Este vértice é realmente um vértice?”
isinstance()WebpageGitHubRepository

Tendo escrito ou gerado automaticamente um esquema e implementado essas quatro funções, estamos prontos para consultar qualquer conjunto de dados com uma linguagem de consulta rápida e moderna!
Nós apenas arranhamos a superfície!
Pule para este capítulo do vídeo.
Ter todos os nossos dados disponíveis em um único sistema de consulta nos dá uma enorme quantidade de alavancagem para criar ferramentas interessantes. Nesta palestra, apenas arranhamos a superfície do que é possível com essa tecnologia. $^11$
Vou dar alguns breves exemplos de alguns dos casos de uso mais inesperados.

Um deles é nossa capacidade de consultar esquemas, consultas e planos de consulta.
Assim como podemos consultar os dados por trás de uma API, também podemos consultar a forma dos próprios dados. Podemos fazer perguntas como:
- Qual de nossas consultas aplica filtros na propriedade do tipo?
XY - Quais tipos em nosso esquema têm campos digitados em string com nomes que terminam em ?
date
O outro exemplo é que podemos usar o rastreamento de consulta de gravação e reprodução para nos ajudar a entender, auditar e depurar nossas consultas.
Na verdade, isso é uma grande parte de como funciona o próprio conjunto de testes da Trustfall! Registramos rastreamentos que capturam todas as operações executadas como parte da execução de todas as nossas consultas de teste e, em seguida, reproduzimos os rastreamentos em nosso interpretador como um teste de instantâneo para garantir que seu comportamento não tenha mudado. Os rastreamentos são um registro linearizado e legível que mostra quais dados foram produzidos e quando e são perfeitos para garantir a exatidão do Trustfall e de seus adaptadores.
Se você quiser se aprofundar, confira:
- Página do GitHub da Trustfall: https://github.com/obi1kenobi/trustfall
- O código de demonstração para esta palestra: https://github.com/obi1kenobi/trustfall/tree/main/demo-hytradboi
- Nossos playgrounds, onde você pode consultar APIs do HackerNews ou o conteúdo de pacotes populares do Rust
cargo-semver-checks, um linter para versionamento semântico em Rust escrito usando Trustfall e o assunto de outras palestras que dei
O Trustfall nos dá uma quantidade sem precedentes de alavancagem, diferente de qualquer coisa que as ferramentas de código aberto poderiam usar antes. É uma peça fundamental de infraestrutura para ferramentas poderosas e, até agora, apenas arranhamos a superfície!
Se você gostou deste post, considere se inscrever no meu blog ou me seguir no Mastodon, Bluesky ou Twitter/X. Estou dando uma palestra relacionada na UA Rust Conference 2024, então não deixe de conferir!
- Como não estou mais empregado nessa empresa, tudo neste post é escrito a título pessoal e pode não representar as opiniões passadas ou presentes do meu empregador anterior. Além disso, não leia muito sobre a minha partida - eu estive lá por 7 + anos, saí em bons termos, e muitos dos meus amigos ainda trabalham lá.
- Acredito que Simon Willison cunhou o termo “conversa comentada” e o descreveu em seu blog. Gosto dessa ideia e pretendo seguir a mesma abordagem.
- Deixei a Kensho no final de 2022, depois de ingressar como uma pequena startup e vê-la crescer ao longo de 7 anos. Mas dei essa palestra em abril de 2022, quando Kensho ainda era meu empregador.
- Este era o número correto no momento em que dei esta palestra. Quando saí da Kensho, cerca de 6 meses depois, esse número havia crescido substancialmente.
- Outra observação: esse sistema mudou nosso ponto de vista coletivo de, em termos gerais, “incidentes acontecem” para “espere, como poderíamos ter evitado isso?” Se prevenir problemas parece caro, não se tentaria evitá-los e, em vez disso, aprende-se a conviver com eles. Mas quando a prevenção de repente se tornou ordens de magnitude mais baratas, nos vimos preenchendo novos cheques após cada incidente ou quase acidente.
- Mais uma vez, observe que esta é uma palestra que dei em 2022 enquanto ainda trabalhava lá. Não sou mais funcionário da Kensho e não posso falar pelo meu ex-empregador.
- A maioria das ferramentas de eliminação de código morto só pode encontrar código morto em uma única unidade, como uma biblioteca ou um serviço. As consultas nos permitiram escrever análises entre componentes, e eu fiquei muito bom no jogo de “eliminação de código morto por meio de consultas”! Quando deixei a Kensho, cerca de 6 meses depois de dar esta palestra, eu tinha a segunda maior métrica de contribuição de linhas líquidas negativas: eu havia excluído mais de 200 mil linhas a mais do que havia adicionado. Nada mal para 7 anos de trabalho!
- Agora, você pode estar se perguntando: se eu fiquei em segundo lugar na métrica líquida negativa, quem ficou em primeiro lugar? A resposta: meu gerente, que uma vez encontrou e excluiu um arquivo JSON de 600 mil linhas que alguém havia comprometido com o monorepo. Eu não tinha essas balas de prata, então a lacuna era intransponível :)
- Nossa demonstração foi codificada para retornar apenas 20 resultados, mas as consultas do Trustfall são avaliadas preguiçosamente, portanto, não é necessário especificar um número específico de resultados desejados antecipadamente. A execução de uma consulta retorna um iterador que produz lentamente os resultados da consulta. Se o iterador estiver esgotado, todos os resultados possíveis serão recuperados. Se um resultado parcial for suficiente, pode-se interromper o avanço do iterador a qualquer momento.
- Por exemplo, o adaptador JSON rustdoc que alimenta pode ser encontrado neste repositório. Seu esquema está aqui e precisa implementar a API Trustfall definida aqui. Sua implementação está aqui. Esta é uma das implementações de adaptador mais complexas, uma vez que precisa modelar com precisão a maior parte da semântica da linguagem Rust para fins de verificação semver! Não foi construído monoliticamente de uma só vez e, em vez disso, cresceu em escopo organicamente ao longo de vários anos.
cargo-semver-checksAdapterAdapter - Hoje, o linter
cargo-semver-checkspara versionamento semântico em Rust é outro exemplo das possibilidades que o Trustfall desbloqueia.