Humanos no loop de IA - os rotuladores de dados por trás de alguns dos conjuntos de dados de treinamento dos LLMs mais poderosos
Quem são os trabalhadores por trás dos conjuntos de dados de treinamento que alimentam os maiores LLMs do mercado? Neste explicador, nos aprofundamos na rotulagem de dados como parte da cadeia de suprimentos de IA, os trabalhadores por trás dessa rotulagem de dados e como esse ecossistema de trabalho explorador funciona, auxiliado por algoritmos e questões de governança sistêmica maiores que exploram microtrabalhadores na economia gig.
Pontos-chave
- Dados de treinamento de alta qualidade são o elemento crucial para produzir um LLM de desempenho, e os dados de treinamento de alta qualidade são rotulados como conjuntos de dados.
- Várias plataformas de trabalho digital surgiram para a tarefa de fornecer rotulagem de dados para o treinamento LLM. No entanto, a falta de transparência e o uso de modelos algorítmicos de tomada de decisão sustentam seus modelos de negócios exploradores.
- Os trabalhadores muitas vezes não são informados sobre quem ou para o que estão rotulando conjuntos de dados brutos e são submetidos a vigilância algorítmica e sistemas de tomada de decisão que facilitam a estabilidade não confiável no emprego e salários imprevisíveis.
Por trás de cada máquina está uma pessoa humana que faz as engrenagens dessa máquina girarem - há o desenvolvedor que constrói (codifica) a máquina, os avaliadores humanos que avaliam o desempenho da máquina básica, até mesmo as pessoas que constroem as peças físicas para a máquina. No caso de grandes modelos de linguagem (LLMs) que alimentam seus sistemas de IA, essa “pessoa humana” são os rotuladores de dados invisíveis de todo o mundo que estão anotando manualmente conjuntos de dados que treinam a máquina para reconhecer qual é a cor “azul”, quais objetos estão em uma fotografia ou se a resposta de um chatbot é adequada.
Com a rápida expansão e desenvolvimento de LLMs, a resposta dos desenvolvedores de IA tem sido ampliar seus métodos de treinamento para serem mais rápidos e inteligentes. Neste explicador, nos aprofundamos na rotulagem de dados como parte da cadeia de suprimentos de IA, os trabalhadores por trás da rotulagem de dados e como funciona esse ecossistema de trabalho explorador.
Antecedentes: as etapas de formação de um LLM
Grandes modelos de linguagem (LLMs) são modelos avançados de aprendizado de máquina, como GPT-4, projetados para entender e gerar conteúdo como um ser humano. Os LLMs são treinados em grandes quantidades de dados para permitir que capturem padrões complexos na linguagem para executar uma ampla variedade de tarefas relacionadas à linguagem natural. Eles podem ser treinados para fins específicos, como fornecer respostas de chatbot, prever texto na redação de e-mails ou resumir material textual ou verbal.
Em alto nível, os três estágios de treinamento por trás de tal LLM são: 1) aprendizado auto-supervisionado; 2) ajuste fino (aprendizado supervisionado); 3) aprendizado por reforço.
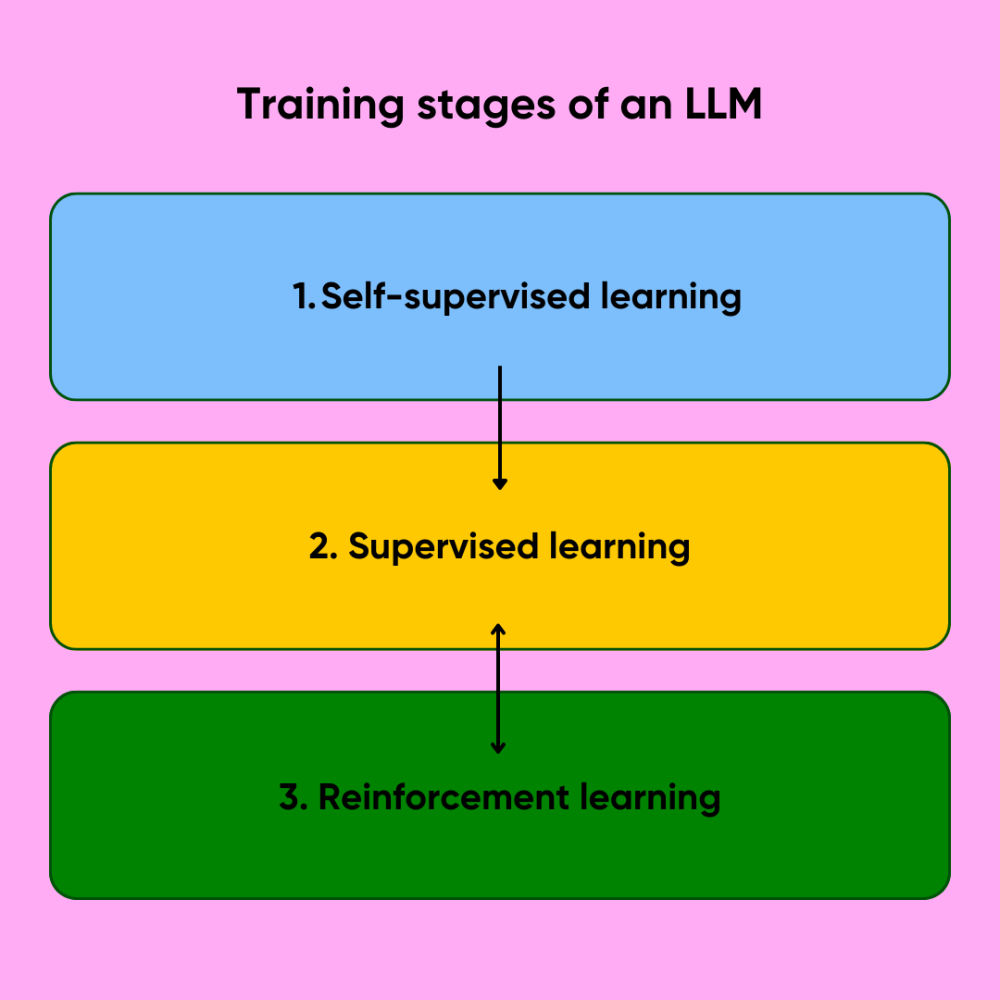
Figura 1. Três estágios de treinamento de um grande modelo de linguagem.
O aprendizado auto-supervisionado é o estágio em que o modelo básico de base é construído a partir de dados brutos, não rotulados, mas com curadoria, normalmente um banco de dados massivo como os do rastreamento da web (por exemplo, Common Crawl) ou conjuntos de dados selecionados como The Pile. Os próximos estágios de ajuste fino (aprendizado supervisionado e por reforço) são onde entra o trabalho humano. O aprendizado supervisionado envolve o treinamento do modelo de IA em relação a um conjunto de dados rotulado, cujos elementos são rotulados por anotadores humanos, para que o modelo aprenda as respostas “certas” das erradas. Isso é complementado pelo aprendizado por reforço com feedback humano (RLHF), que envolve, entre outras etapas, avaliadores humanos criando um conjunto de dados de treinamento supervisionado a partir de prompts especificados, respostas e classificações avaliadas por humanos contra as quais o modelo deve se reciclar. Para criar um conjunto de dados de treinamento supervisionado, os rotuladores de dados marcam pontos de dados brutos (imagens, texto, dados de sensores, etc.) com “rótulos” que ajudam o modelo de IA a tomar decisões cruciais, como para um veículo autônomo distinguir um pedestre de um ciclista.
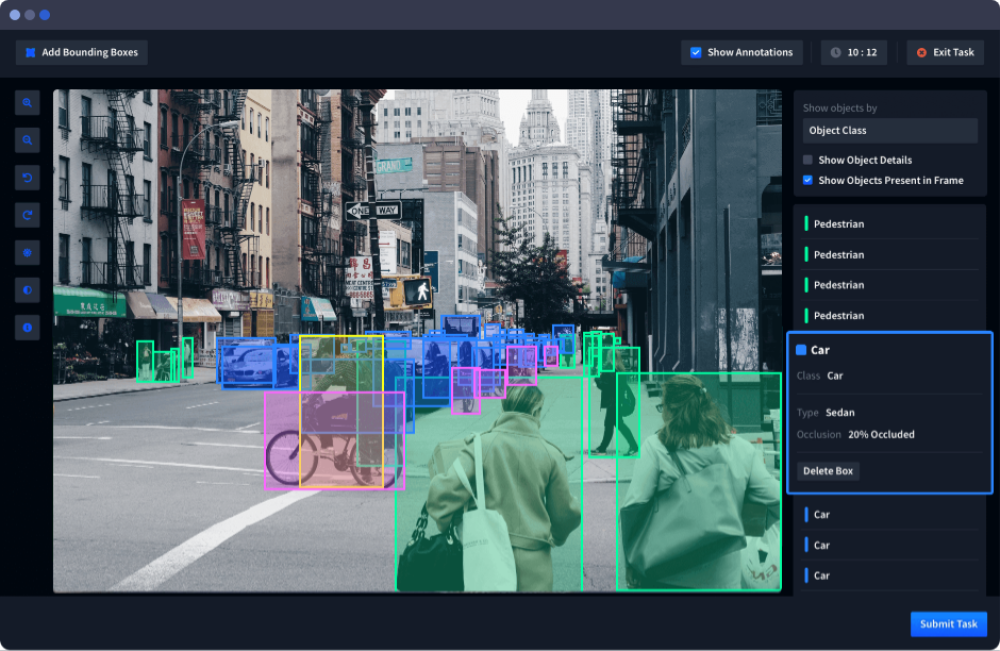
Figura 2. Captura de tela do software de rotulagem de dados do Neptune AI como um exemplo de como pode ser um painel de tarefas de rotulagem.
Os modelos podem ser continuamente treinados novamente por meio da iteração do feedback humano para ajustar ainda mais comportamentos inadequados e tornar o modelo mais robusto, como a OpenAI ser capaz de detectar e prevenir jailbreaks. Conjuntos de dados de alta qualidade suportados por humanos no circuito (rotulagem) são cruciais para esse processo de treinamento e retreinamento para garantir saídas precisas, consistentes e completas. Dados de baixa qualidade podem resultar em um modelo produzindo resultados incorretos ou desfavoráveis, como respostas tendenciosas ou inconsistentes.
Diferenciamos duas categorias de rotuladores de dados por trás de conjuntos de dados de treinamento supervisionado: rotuladores de dados não específicos do assunto que anotam conjuntos de dados genéricos em grande escala e rotuladores de dados ‘especialistas’ que anotam conjuntos de dados específicos do assunto. O primeiro tipo de rotulador de dados tem sido o mais comum. Envolve microtrabalhadores contratados de todo o mundo vasculhando horas de conteúdo pelo menos servil, se não hediondo, para anotar conjuntos de dados que podem ser usados para treinar a maioria dos tipos de IA. Esses conjuntos de dados podem ser rotulados para chatbots como ChatGPT, algoritmos de direção autônoma ou geradores de imagem para texto. A segunda categoria de rotuladores de dados é um tipo mais específico que requer especialistas no assunto, como médicos rotulando dados médicos ou advogados rotulando respostas legais, como uma forma especializada de ‘verificação de fatos especializada’. Embora ambas as categorias de rotuladores de dados estejam tecnicamente realizando o mesmo tipo de trabalho (rotulagem de imagens ou texto), elas diferem no nível de conhecimento especializado que pode ser necessário para demandas de rotulagem específicas do domínio.
Rotulagem de dados e a cadeia de suprimentos de IA de geração
Evidentemente, dados de treinamento de alta qualidade são o elemento-chave na criação de um LLM de desempenho. Alguns indivíduos chegaram a dizer que o algoritmo em si importa muito menos do que os dados de treinamento, já que os dados de resultados de conjuntos de dados de treinamento robustos são o que diferencia o desempenho de um LLM.
Várias empresas assumiram a tarefa de facilitar a demanda de rotulagem de dados na cadeia de suprimentos de IA. Essas empresas de dados podem ser categorizadas em dois tipos de mercados de trabalho para o trabalho de rotulagem de dados: 1) plataformas de microtrabalhadores que anunciam uma variedade de empregos, como o Mechanical Turk (AMT) da Amazon, e 2) plataformas emergentes recentemente dedicadas especificamente a trabalhos de rotulagem de dados, como Surge AI, Scale AI (Remotasks), iMerit e Karya.
Plataformas de microtrabalhadores como a AMT funcionam como um mercado de mão de obra na Internet, onde os empregadores podem postar uma variedade de tarefas com um preço anexado para conclusão, como serviços de tradução, rotular as cores em uma foto ou reescrever uma frase. Plataformas dedicadas especificamente a trabalhos de rotulagem de dados, como a Remotasks, uma subsidiária da Scale AI, operam de forma semelhante, atribuindo aos trabalhadores tarefas de rotulagem pagas que variam em escopo e escala (uma tarefa pode ser rotular 100 fotografias, outra pode ser rotular objetos em um vídeo de horas para um algoritmo de veículo autônomo).

Figura 3. Uma captura de tela do anúncio de emprego de rotulagem de dados da Remotasks em seu site.
Essas plataformas de trabalho digital são efetivamente uma alternativa à contratação e gerenciamento de um grande número de funcionários por meio de uma relação contratual, em vez de terceirizar tarefas para trabalhadores humanos sob demanda sem uma relação formal empregador-empregado em um modelo de trabalho humano como serviço. A maioria dessas plataformas opera em um modelo de crowdsourcing de mão de obra, que terceiriza o trabalho para uma rede em constante mudança de “trabalhadores por peça”, ou microtrabalhadores, no lugar de funcionários contratados para realizar tarefas domésticas para a organização maior.
Devido às vastas quantidades de dados rotulados necessários para treinamento supervisionado que empresas de IA como a OpenAI, que contrata os serviços de dados da Scale AI, e a Microsoft, que contrata a Surge AI, exigem, a cadeia de suprimentos de IA se espalhou por toda parte para países como Quênia, Índia, Filipinas e Venezuela com mão de obra mais barata e em maior quantidade. Como discutiremos a seguir, isso resultou na exploração flagrante de ‘humanos como serviço’, onde os trabalhadores são dispensáveis e as empresas podem se safar pagando a eles apenas US $ 2 por hora pelo trabalho de rotulagem que alimenta máquinas de bilhões de dólares.
Por trás do ecossistema de trabalho de rotulagem de dados: da falta de transparência à vigilância algorítmica
A corrida de IA em andamento iniciada pela OpenAI faz com que os desenvolvedores de IA se concentrem em obter seus conjuntos de dados de treinamento rotulados e supervisionados o mais rápido possível, pelo mais barato possível. Disfarçados por trás da retórica corporativa de oportunidades de emprego em expansão e salários acima do salário mínimo (uma promessa não tão bem cumprida), os desenvolvedores de IA exploram uma força de trabalho ansiosa para alimentar sua demanda intensiva por dados de treinamento rotulados. Essa demanda se traduz em um mercado de trabalho explorador. Enquanto os trabalhadores ficam com uma fonte não confiável de trabalho, salários mal pagos e condições de trabalho desafiadoras, os principais players de IA enfrentam pouca ou nenhuma responsabilidade.
Falta de transparência em torno do trabalho: os trabalhadores não sabem para quem e para qual máquina estão rotulando
Exacerbando o desequilíbrio de poder entre o trabalhador explorado e o desenvolvedor de IA explorador está a falta de transparência em torno da relação da cadeia de suprimentos entre as plataformas de trabalho de rotulagem de dados e seus principais clientes que exigem conjuntos de dados rotulados de alta qualidade. Uma investigação de 2023 do The Verge descobriu que os rotuladores de dados no Quênia que concluíram tarefas de rotulagem para Remotasks não sabiam que a Remotasks era de fato uma subsidiária da empresa de dados mais conhecida Scale AI, que possui clientes como OpenAI, Meta, Microsoft e até agências governamentais dos EUA. A Remotasks também não é mencionada em nenhum lugar do site da ScaleAI ou da ScaleAI no site da Remotasks, obscurecendo cuidadosamente seu relacionamento comercial aos olhos do público. Essa falta de transparência em torno das relações comerciais opacas entre empresas de dados e suas subsidiárias é uma tendência comum, já que a Surge AI, uma empresa de dados semelhante, também foi especulada como a suposta empresa-mãe de plataformas menores Taskup.ai e DataAnnotation.tech que usa para contratar rotuladores de dados. Isso obscurece o relacionamento da cadeia de suprimentos entre o cliente final (Open AI) e os microtrabalhadores que fornecem seus conjuntos de dados. Para garantir que essas relações comerciais sejam mantidas opacas, os rotuladores de dados são advertidos contra revelar muito sobre seu trabalho.
Com efeito, os rotuladores de dados estão completamente desconectados dos desenvolvedores de IA que exigem seu trabalho, e essa opacidade no relacionamento da cadeia de suprimentos de IA, uma tendência que vimos em outros setores, como a cadeia de suprimentos de semicondutores, permite uma falta de supervisão e responsabilidade para com os microtrabalhadores. Os trabalhadores não recebem informações e divulgações adequadas sobre seu emprego e por quem seu trabalho será usado. Isso é ainda mais agravado pelo fato de que a mesma investigação do The Verge descobriu que alguns trabalhadores quenianos nem sabiam para que estavam rotulando os dados. Rotular peças de roupa, escolher pedestres em um vídeo ou categorizar diálogos eram pequenas peças de um projeto maior para o qual eles não sabiam o que estavam treinando uma IA para fazer - e os nomes dos próprios projetos estavam escondidos atrás de codinomes indecifráveis como ‘Geração de Caranguejo’ ou ‘Pillbox Bratwurst’.
Falta de transparência em torno da Tomada de Decisão Automatizada (ADM)
Há também uma falta de transparência em torno dos algoritmos que vigiam a produtividade dos trabalhadores e tomam decisões importantes para sua alocação de empregos e salários. O gerenciamento algorítmico, vagamente definido como um conjunto de técnicas de vigilância tecnológica para gerenciar forças de trabalho e tomar decisões automatizadas ou semiautomatizadas sobre o comportamento dos trabalhadores, é cada vez mais implantado no local de trabalho contemporâneo. As empresas contam com algoritmos para vigiar e monitorar a produtividade e o desempenho dos funcionários no local de trabalho, como na forma de ‘bossware’, como rastreadores de mouse para trabalhadores remotos, cronômetros para trabalhadores de armazém da Amazon e software de reconhecimento facial para monitorar a expressão ou o humor de um funcionário no local de trabalho. No contexto da economia gig, esses algoritmos têm o poder de tomar decisões críticas que afetam os trabalhadores, como suspender a conta de um motorista de entrega sem explicação ou decidir quanto um motorista do Uber pode receber por uma corrida, dependendo da hora do dia.
Muitas plataformas de trabalho de rotulagem de dados são alimentadas por esses modelos de tomada de decisão algorítmica (ADM) em vez de uma pessoa humana gerenciando a administração de todas as fases do processo de trabalho, desde sistemas opacos de alocação de empregos até modelos dinâmicos de preços de aumento para definir salários.
Como documentamos anteriormente em nosso escrutínio da economia gig, os modelos de caixa preta da ADM sujeitam os trabalhadores, que não recebem informações nem uma compreensão clara do algoritmo que rege seu emprego, a condições de trabalho injustas, estabilidade no emprego não confiável e salários instáveis que ameaçam sua privacidade e liberdades.
Vigilância do trabalhador
As plataformas de trabalho de rotulagem de dados variam no uso da vigilância no local de trabalho, mas os trabalhadores na Venezuela e na Colômbia relataram ter sido submetidos a cronômetros rígidos durante o trabalho - cronômetros que muitas vezes não acomodavam pausas para ir ao banheiro - para monitorar a eficiência com que estavam concluindo suas tarefas de rotulagem. Sua falha em concluir as tarefas no tempo alocado resultou na realocação da tarefa para o conjunto de tarefas para outros tomadores. A MIT Technology Review testou isso criando uma conta no Remotasks e notou um cronômetro no canto superior esquerdo da tela, visivelmente ‘sem um prazo claro ou maneira aparente de pausá-lo para ir ao banheiro’. Isso foi interpretado como um ‘temporizador de inatividade’ que envia a tarefa de volta para o pool de tarefas na plataforma para outra pessoa reivindicar se um trabalhador a deixar incompleta por muito tempo. Esse tipo de vigilância granular, sem explicação aparente de como funciona, coloca os trabalhadores sob pressão para competir com os outros, permitindo assim um sistema explorador para as empresas obterem sua produção da maneira mais rápida possível, às custas da saúde mental e do bem-estar físico dos trabalhadores. Sem mencionar que os trabalhadores não têm uma visão de como exatamente esse algoritmo de vigilância funciona, então a lacuna de conhecimento os coloca em uma posição difícil para contestar seu uso.
Além disso, a complexidade de certas tarefas de rotulagem, como marcar se o reflexo de uma camisa no espelho deve ser rotulado como uma peça de roupa, leva pessoas diferentes um tempo diferente para decifrar. Consequentemente, esse tipo de ambiente altamente pressurizado pode excluir um setor significativo da força de trabalho punido por essa vigilância intrusiva no local de trabalho.
Estabilidade de emprego não confiável
A implantação intensiva de ferramentas de gerenciamento algorítmico, como monitores de inatividade, que criam pressão indevida sobre os trabalhadores às custas de seu próprio bem-estar, também perpetua um ecossistema de empregos instável. Os algoritmos de alocação determinam quais trabalhadores podem ser elegíveis para reivindicar quais tarefas com base em métricas como seu desempenho. Para algumas plataformas de microtrabalhadores de rotulagem de dados, como o Appen, não há um sistema claro para quando as tarefas aparecem na fila, portanto, os microtrabalhadores devem monitorar ininterruptamente suas telas para reivindicar um trabalho no momento em que ele aparece inesperadamente. Um anotador do Remotasks no Quênia chegou a dizer que adquiriu o hábito de acordar a cada poucas horas à noite para verificar sua fila de tarefas porque muitos trabalhos aparecem, sem aviso prévio, tarde da noite. Embora uma investigação da Fairwork tenha creditado a Remotasks por ‘gerenciar a disponibilidade de empregos’ com base em evidências de que uma equipe se dedica a sugerir novos empregos aos trabalhadores com base nas características do perfil, recomendar novos empregos aos trabalhadores não nega o fato de que os trabalhadores recorreram a hábitos humilhantes e prejudiciais de interromper o sono para verificar sua fila de tarefas e também correr contra o relógio ao realizar tarefas para evitar o risco dessas mesmas tarefas sendo empurradas de volta para a fila devido à sua velocidade de conclusão. O modelo de trabalho de microtrabalhadores humanos como serviço exacerba as condições de trabalho insustentáveis que os rotuladores de dados devem suportar.
A falta de transparência e divulgação de informações aos trabalhadores sobre algoritmos de alocação de empregos foi investigada pela Fairwork no mesmo relatório acima, que observou que nenhuma das plataformas de microtrabalho analisadas disponibilizou informações aos trabalhadores sobre como o trabalho foi alocado e quando os algoritmos foram usados. Como os trabalhadores podem desafiar essas condições ou agir de outra forma se não sabem como os algoritmos funcionam e só podem especular sobre em quais cenários são implantados?
Esse modelo de alocação explorador é sintomático do modelo de governança mais amplo favorecido pelas empresas ocidentais que transferem sua força de trabalho em países e regiões com proteções e benefícios legais mais fracos para os trabalhadores. Na verdade, muitas empresas nem mesmo informam os trabalhadores de sua decisão de mudar para um mercado diferente e praticamente desaparecem da noite para o dia. A falta de responsabilidade para com os trabalhadores sobre essas decisões de governança desestabiliza ainda mais o mercado de trabalho para rotuladores de dados que já estão lutando com 1) competir por tarefas disponíveis e 2) concluir tarefas suficientes por dia para ganhar um salário digno (menos que o mínimo). Outro anotador no Quênia relatou que as tarefas estavam secando na região, e ficou claro que a cadeia de suprimentos de IA, que tinha a vantagem de não ter uma infraestrutura local, estava migrando para outros países com mão de obra mais barata, como Nepal e Filipinas (até que o próximo mercado mais barato apareça e eles se estabeleçam lá). A natureza fluida da cadeia de suprimentos de IA significa que ela pode funcionar como “uma linha de montagem que pode ser reconfigurada infinita e instantaneamente, movendo-se para onde quer que haja a combinação certa de habilidades, largura de banda e salários”. E no processo dessas peças de mudança (rotuladores de dados) na linha de montagem, as empresas nunca informam os trabalhadores sobre as decisões de governança de mudar para um novo mercado depois de apenas alguns meses antes de atraí-los com aquele refrão corporativo de oportunidades de emprego promissoras e bons salários.
Salários modelo de aumento
Também houve relatos de algoritmos que definem salários dinâmicos em plataformas de trabalho de rotulagem de dados. Os trabalhadores da Remotask, por exemplo, especularam que seu pagamento pode ser determinado por algoritmos, e isso foi confirmado por ex-funcionários da Scale AI que disseram que o pagamento foi determinado por meio de ‘um mecanismo semelhante a um aumento de preço que se ajusta a quantos anotadores estão disponíveis e a rapidez com que os dados são necessários’. Este é um modelo de precificação explorador que vemos com frequência em plataformas de economia gig como o Uber, que usa um algoritmo opaco para calcular o pagamento do motorista com base em fatores como “a demanda de passageiro para motorista” e se é um período movimentado. Em ambos os casos, os trabalhadores não têm informações sobre como o algoritmo de precificação dinâmica calcula seus salários; Só a empresa sabe o que realmente se passa dentro da caixa preta. Isso causa prejuízos significativos aos meios de subsistência dos microtrabalhadores, pois uma viagem que pode pagar £ 26 para um motorista pode pagar £ 46 para outro pela mesma viagem. Os trabalhadores são submetidos aos caprichos de um ambiente imprevisível controlado por algoritmos definido pela empresa, privando-os de agência e autonomia, pois seus salários e oportunidades de emprego são determinados por um algoritmo dinâmico que eles não entendem.
Tudo volta para a economia gig
Evidentemente, os problemas que estamos vendo com o ecossistema de rotulagem de dados são os mesmos sintomas que temos visto do trabalho de plataforma na economia gig. Por um lado, há as condições de trabalho intrusivas e exploradoras (por exemplo, temporizadores rígidos que inibem as pausas para ir ao banheiro) que vimos de forma semelhante nas condições de trabalho dos trabalhadores do armazém da Amazon ou dos moderadores de conteúdo do Facebook. Isso é exacerbado (e facilitado) pela falta de um contrato claro e termos e condições justos para os microtrabalhadores, com alguns rotuladores de dados se manifestando sobre como foram discretamente fantasmas de seus gerentes sem explicação. Essa relação exploradora empregador-empregado cria um ambiente instável e não confiável que os trabalhadores, desinformados e sem contrato de trabalho formal, têm poucos meios para desafiar.
Depois, há também a questão dos salários dinâmicos e não padronizados (também agravados pela falta de um contrato claro). O modelo de precificação dinâmica sujeita os trabalhadores a um fluxo de renda não confiável e imprevisível à mercê de um algoritmo de caixa preta sobre o qual eles não têm informações. O que uma tarefa pode pagar pode ser o dobro ou a metade de outra no dia seguinte, e os trabalhadores não podem prever isso nem entendê-lo. Também não se pode ignorar que as plataformas de microtrabalhadores normalmente recebem uma certa porcentagem do pagamento da tarefa do trabalhador para si mesmas, e os trabalhadores geralmente não são informados sobre qual é essa porcentagem e como ela é calculada.
Há também a questão da remuneração inadequada no caso de cursos de formação não remunerados. Muitas plataformas de rotulagem de dados exigem que os novos trabalhadores concluam cursos de treinamento não remunerados antes de se qualificarem para tarefas remuneradas, mas os participantes notaram que esses cursos levam uma quantidade significativa de tempo, complicados por longos testes e instruções conflitantes (por exemplo, os reflexos de camisas no espelho são considerados camisas em uma foto?) sintomáticos do pensamento mecânico que as máquinas de pensamento exigem Na verdade, a investigação da Fairwork descobriu que 250 rotuladores de dados pesquisados gastaram mais de 6 horas em média em atividades não remuneradas, incluindo procurar emprego e fazer testes de qualificação não remunerados.
Em um nível mais amplo, além do modelo de precificação algorítmica, também está simplesmente a falta de um mecanismo salarial padronizado endossado pelo modelo de governança capitalista. Isso pode ser visto nas disparidades salariais escancaradas entre os países (por exemplo, salários nos EUA para uma tarefa em comparação com os salários do Quênia) e até mesmo dentro dos países entre diferentes tipos de rotulagem especializada (por exemplo, US$ 23 por hora para falantes especializados de finlandês versus US$ 5,64 para escritores búlgaros especializados). Além disso, os rotuladores de dados no Quênia relataram ter sido repentinamente descartados pela Remotasks quando a empresa deixou o mercado queniano, com horas de salários que não foram pagas aos trabalhadores e falta de mecanismos de reparação para recuperar esses salários.
Essa falta de salários padronizados também levanta preocupações maiores em torno do abuso e exploração do mercado de trabalho global de microtrabalhadores. Enquanto os anotadores baseados nos EUA podem ganhar de US$ 10 a US$ 25 por hora pelo mesmo tipo de trabalho, os anotadores quenianos podem estar ganhando apenas US$ 2 por hora - sem nem mesmo saber que a empresa para a qual estão rotulando os dados é uma corporação tão grande quanto a OpenAI. Em maio de 2024, 97 rotuladores de dados, moderadores de conteúdo e trabalhadores de IA em Nairóbi escreveram uma carta aberta ao presidente Biden no 60º aniversário das relações diplomáticas EUA-Quênia, apresentando uma lista de demandas para lidar com a exploração e o abuso de trabalhadores quenianos na cadeia de suprimentos da Big Tech dos EUA. Eles detalham a natureza cansativa de seu trabalho, incluindo ‘rotular] imagens e texto para treinar ferramentas generativas de IA como o ChatGPT para OpenAI. Nosso trabalho envolve assistir a assassinatos e decapitações, abuso infantil e estupro, pornografia e bestialidade, muitas vezes por mais de 8 horas por dia, por menos de US$ 2 por hora.
O futuro da rotulagem de dados na economia dos microtrabalhadores
Há muitas outras preocupações ainda a serem abordadas em torno da natureza exploradora e intensiva do mercado de trabalho de rotulagem de dados. Além das questões que discutimos em torno da vigilância no local de trabalho, alocação algorítmica de empregos e salários não padronizados, há também o bem-estar dos trabalhadores rotulando conteúdo violento ou gráfico e a falta de uma relação contratual formalizada com os empregadores que concede aos trabalhadores direitos como reparação.
Rotulagem automatizada de dados
É incerto como o cenário de trabalho de rotulagem de dados pode evoluir. Há esforços crescentes para automatizar a rotulagem de dados para aumentar e expandir ainda mais sua capacidade e alcance. Um desses métodos automatizados é a rotulagem assistida, que envolve o uso de algoritmos de aprendizado de máquina que podem identificar padrões e tendências nos dados para pré-rotular pontos de dados que serão repassados a avaliadores humanos para aprovação ou rejeição. Funcionalmente, esta é apenas uma versão ligeiramente simplificada do esquema de rotulagem humana existente.
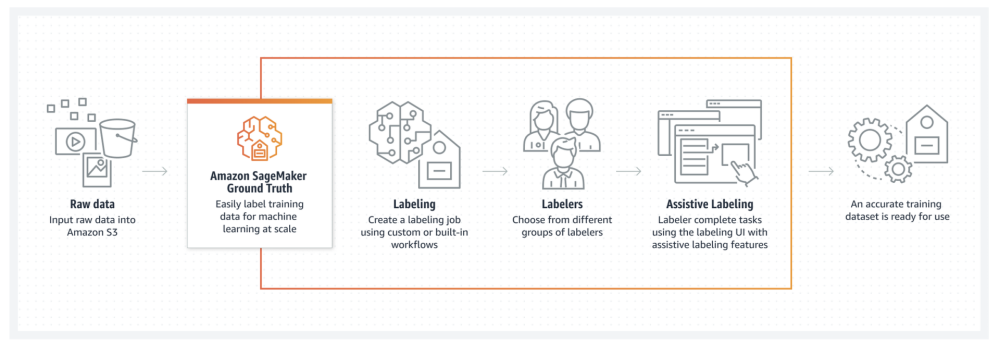
Figura 4. Captura de tela do modelo de rotulagem assistida do Amazon Sagemaker Ground Truth.
A rotulagem assistida normalmente é implantada em combinação com o aprendizado ativo, outro método automatizado de rotulagem de dados, como o oferecido pelo Amazon Sagemaker Ground Truth, que faz com que os humanos anotem um conjunto de dados não rotulado para criar um modelo validado usado para “rotulagem automática” que gerará pontuações de confiança como um limite para comparar conjuntos de dados não rotulados, que serão executados recursivamente nesse processo de rotulagem automática com base nessas pontuações de confiança.
Outras empresas estão explorando a rotulagem programática, que utiliza funções de rotulagem para anotar pontos de dados, combinando chamadas lógicas para categorias conhecidas especificadas (por exemplo, verificação ortográfica de uma resposta) e abstendo-se de outras para passar para rotuladores humanos para anotação. Este método visa reduzir a quantidade de rotulagem manual exigida pelos rotuladores humanos.
No entanto, todas essas técnicas acima para automatizar a rotulagem de dados ainda exigem um humano no circuito até certo ponto. É difícil determinar como isso pode afetar os trabalhadores - poderia melhorar as condições de trabalho protegendo os rotuladores de certos tipos de conteúdo prejudicial e reduzindo o tempo de rotulagem, mas isso não alivia nenhum dos abusos hegemônicos maiores da economia gig que explora os microtrabalhadores. Os rotuladores humanos ainda serão necessários até certo ponto enquanto a IA existir, e a automação de algumas tarefas de rotulagem não melhorará a estrutura salarial dinâmica imprevisível dos trabalhadores, nem o ecossistema de alocação de empregos, nem o fato de que eles podem continuar a ser vigiados por algoritmos em seu desempenho do trabalho. Automatizar a rotulagem de dados, mais uma vez, foi apenas um movimento das grandes empresas para aumentar sua própria eficiência e produtividade, não para atender às preocupações dos trabalhadores.
Olhando para o futuro no cenário regulatório
O futuro da indústria de rotulagem de dados pode muito bem ser uma questão da cadeia de suprimentos de IA como um todo e como o cenário regulatório responderá a isso. Com a crescente demanda por conjuntos de dados rotulados de alta qualidade, é difícil dizer como o ecossistema de trabalho para rotulagem de dados pode mudar para melhor atender aos direitos dos trabalhadores explorados por uma cadeia de suprimentos exigente. Vemos isso em vários setores, nos quais as empresas exploram conscientemente os trabalhadores para atender às necessidades de sua cadeia de suprimentos e evitam a responsabilidade pelas condições de trabalho desses trabalhadores no terreno, como no caso da perigosa mineração de cobalto para a produção de baterias.
Os rotuladores de dados estão carregando a cadeia de suprimentos de IA nas costas e, no entanto, seu status no ecossistema da economia gig significa que eles podem e serão explorados por algoritmos de caixa preta e condições de trabalho irracionais. A luta por um melhor tratamento dos microtrabalhadores na economia gig tem sido longa, repleta de mais e mais plataformas surgindo em diferentes setores mais rapidamente do que a política pode acompanhar; demorou anos para que o Parlamento Europeu sequer considerasse consagrar os direitos dos trabalhadores das plataformas na forma da Diretiva Trabalho nas Plataformas. A Organização Internacional do Trabalho (OIT) publicou um relatório sobre a realização do trabalho decente na economia de plataforma (a ser discutido nas Conferências Internacionais do Trabalho de 2025 e 2026) que pode levar a uma nova norma internacional do trabalho com base na forma como os países estão abordando a prevalência e os desafios do trabalho em plataforma. Como o modelo de microtrabalhador é cada vez mais utilizado por grandes empresas de IA que buscam rotulagem de conjuntos de dados barata e rápida, é importante que a política e a defesa acompanhem o ritmo, expondo as práticas prejudiciais e exploradoras das plataformas de rotulagem de dados e de suas empresas-mãe.